地理情報プロファイル Ver.2.XでフォーマットされたDEMデータのビュワーを作ってみた。
というか手段(webGL)が完璧に目的化しているけど。。。
とりあえず形には、なったので公開。
本当は、file apiでクライアント側のテキスチャ画像を選択できる様にしたかったが、サーバー上の画像ファイルしか貼れないのがthree.jsの仕様らしく断念。
いや違うまたは、別の方法があればどなたか教えてください。
2013年12月2日月曜日
2013年11月9日土曜日

2013年10月22日火曜日
[c] (広義の)コンパイルの工程
分かっていなかった事が分かったので
コンパイルの工程を復習するために hello.cに依存しているtest.cのコンパイル過程を
FreeBSD 9.1 RELEASE で出力してみた。
-hello.h-
#ifndef HELLO_H
#define HELLO_H
int sayHello(void);
#endif
-hello.c-
#include "stdio.h"
#include "hello.h"
int
sayHello(void)
{
printf("hello\n");
return 0;
}
-test.c-
#include <stdio.h>
#include "hello.h"
int
main(int argc, char **argv)
{
sayHello();
return 0;
}
なお、あらかじめhello.cは中間ファイル(オブジェクトコード)hello.oを生成済み。
$ gcc -o test -save-temps -v hello.o test.c
-save-temps … 通常は、削除される中間ファイルをカレントディレクトリに残す
-v … 途中コマンドを標準エラー出力にコマンドのバージョン情報も含めて出力する
以下が出力したコマンド
Using built-in specs.
Target: amd64-undermydesk-freebsd
Configured with: FreeBSD/amd64 system compiler
Thread model: posix
gcc version 4.2.1 20070831 patched [FreeBSD]
/usr/libexec/cc1 -E -quiet -v -D_LONGLONG test.c -fpch-preprocess -o test.i #1
#include "..." search starts here:
#include <...> search starts here:
/usr/include/gcc/4.2
/usr/include
End of search list.
/usr/libexec/cc1 -fpreprocessed test.i -quiet -dumpbase test.c -auxbase test -version -o test.s #2
GNU C version 4.2.1 20070831 patched [FreeBSD] (amd64-undermydesk-freebsd)
compiled by GNU C version 4.2.1 20070831 patched [FreeBSD].
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: a8daf30220ba0c32c21af96787b683e6
/usr/bin/as -V -Qy -o test.o test.s #3
GNU assembler version 2.17.50 [FreeBSD] 2007-07-03 (x86_64-unknown-freebsd) using BFD version 2.17.50 [FreeBSD] 2007-07-03
/usr/bin/ld --eh-frame-hdr -V -dynamic-linker /libexec/ld-elf.so.1 -o test /usr/lib/crt1.o /usr/lib/crti.o /usr/lib/crtbegin.o -L/usr/lib -L/usr/lib hello.o test.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/crtend.o /usr/lib/crtn.o #4
GNU ld 2.17.50 [FreeBSD] 2007-07-03
Supported emulations:
elf_x86_64_fbsd
elf_i386_fbsd
#1 プリプロセス
cc1 がコンパイラ本体らしい
以下が出力されたtest.i の一部
マクロ展開とインクルードファイルの中身の出力が行われていることが確認できる。
# 1 "test.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "test.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 39 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/sys/cdefs.h" 1 3 4
# 40 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/sys/_null.h" 1 3 4
# 41 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/sys/_types.h" 1 3 4
# 33 "/usr/include/sys/_types.h" 3 4
# 1 "/usr/include/machine/_types.h" 1 3 4
# 51 "/usr/include/machine/_types.h" 3 4
typedef signed char __int8_t;
typedef unsigned char __uint8_t;
typedef short __int16_t;
typedef unsigned short __uint16_t;
typedef int __int32_t;
=中略=
# 2 "test.c" 2
# 1 "hello.h" 1
int sayHello(void);
# 3 "test.c" 2
int
main(int argc, char **argv)
{
sayHello();
return 0;
}
#2 アセンブリコード生成
-test.s-
.file "test.c"
.text
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB3:
pushq %rbp
.LCFI0:
movq %rsp, %rbp
.LCFI1:
subq $16, %rsp
.LCFI2:
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
call sayHello
movl $0, %eax
leave
ret
.LFE3:
.size main, .-main
.section .eh_frame,"a",@progbits
.Lframe1:
.long .LECIE1-.LSCIE1
.LSCIE1:
.long 0x0
.byte 0x1
.string "zR"
.uleb128 0x1
.sleb128 -8
.byte 0x10
.uleb128 0x1
.byte 0x3
.byte 0xc
.uleb128 0x7
.uleb128 0x8
=以下略=
#3 アセンブル
アセンブルのコードを機械語に変換 オブジェクトファイル(*.o)を出力する
#4 リンク
必要なライブラリをリンクして、最終的な実行形式ファイル(ELF)を出力する。
以下は、出力されたバイナリに依存する共有ライブラリを表示
$ ldd test
test:
libc.so.7 => /lib/libc.so.7 (0x800819000)
コンパイルの工程を復習するために hello.cに依存しているtest.cのコンパイル過程を
FreeBSD 9.1 RELEASE で出力してみた。
-hello.h-
#ifndef HELLO_H
#define HELLO_H
int sayHello(void);
#endif
-hello.c-
#include "stdio.h"
#include "hello.h"
int
sayHello(void)
{
printf("hello\n");
return 0;
}
-test.c-
#include <stdio.h>
#include "hello.h"
int
main(int argc, char **argv)
{
sayHello();
return 0;
}
なお、あらかじめhello.cは中間ファイル(オブジェクトコード)hello.oを生成済み。
$ gcc -o test -save-temps -v hello.o test.c
-save-temps … 通常は、削除される中間ファイルをカレントディレクトリに残す
-v … 途中コマンドを標準エラー出力にコマンドのバージョン情報も含めて出力する
以下が出力したコマンド
Using built-in specs.
Target: amd64-undermydesk-freebsd
Configured with: FreeBSD/amd64 system compiler
Thread model: posix
gcc version 4.2.1 20070831 patched [FreeBSD]
/usr/libexec/cc1 -E -quiet -v -D_LONGLONG test.c -fpch-preprocess -o test.i #1
#include "..." search starts here:
#include <...> search starts here:
/usr/include/gcc/4.2
/usr/include
End of search list.
/usr/libexec/cc1 -fpreprocessed test.i -quiet -dumpbase test.c -auxbase test -version -o test.s #2
GNU C version 4.2.1 20070831 patched [FreeBSD] (amd64-undermydesk-freebsd)
compiled by GNU C version 4.2.1 20070831 patched [FreeBSD].
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: a8daf30220ba0c32c21af96787b683e6
/usr/bin/as -V -Qy -o test.o test.s #3
GNU assembler version 2.17.50 [FreeBSD] 2007-07-03 (x86_64-unknown-freebsd) using BFD version 2.17.50 [FreeBSD] 2007-07-03
/usr/bin/ld --eh-frame-hdr -V -dynamic-linker /libexec/ld-elf.so.1 -o test /usr/lib/crt1.o /usr/lib/crti.o /usr/lib/crtbegin.o -L/usr/lib -L/usr/lib hello.o test.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/crtend.o /usr/lib/crtn.o #4
GNU ld 2.17.50 [FreeBSD] 2007-07-03
Supported emulations:
elf_x86_64_fbsd
elf_i386_fbsd
#1 プリプロセス
cc1 がコンパイラ本体らしい
以下が出力されたtest.i の一部
マクロ展開とインクルードファイルの中身の出力が行われていることが確認できる。
# 1 "test.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "test.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 39 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/sys/cdefs.h" 1 3 4
# 40 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/sys/_null.h" 1 3 4
# 41 "/usr/include/stdio.h" 2 3 4
# 1 "/usr/include/sys/_types.h" 1 3 4
# 33 "/usr/include/sys/_types.h" 3 4
# 1 "/usr/include/machine/_types.h" 1 3 4
# 51 "/usr/include/machine/_types.h" 3 4
typedef signed char __int8_t;
typedef unsigned char __uint8_t;
typedef short __int16_t;
typedef unsigned short __uint16_t;
typedef int __int32_t;
=中略=
# 2 "test.c" 2
# 1 "hello.h" 1
int sayHello(void);
# 3 "test.c" 2
int
main(int argc, char **argv)
{
sayHello();
return 0;
}
#2 アセンブリコード生成
-test.s-
.file "test.c"
.text
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB3:
pushq %rbp
.LCFI0:
movq %rsp, %rbp
.LCFI1:
subq $16, %rsp
.LCFI2:
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
call sayHello
movl $0, %eax
leave
ret
.LFE3:
.size main, .-main
.section .eh_frame,"a",@progbits
.Lframe1:
.long .LECIE1-.LSCIE1
.LSCIE1:
.long 0x0
.byte 0x1
.string "zR"
.uleb128 0x1
.sleb128 -8
.byte 0x10
.uleb128 0x1
.byte 0x3
.byte 0xc
.uleb128 0x7
.uleb128 0x8
=以下略=
#3 アセンブル
アセンブルのコードを機械語に変換 オブジェクトファイル(*.o)を出力する
#4 リンク
必要なライブラリをリンクして、最終的な実行形式ファイル(ELF)を出力する。
以下は、出力されたバイナリに依存する共有ライブラリを表示
$ ldd test
test:
libc.so.7 => /lib/libc.so.7 (0x800819000)
2013年10月20日日曜日
[FreeBSD] style(9) 単語
man style(9) の翻訳で分からなかった単語の意味を列挙します。
implicit 暗に示す
assume 思い込む
silent on 言及しないで
History is silent on this event. 歴史は、この事件に関しては何も記していない。
brevity 簡潔な
trim 削減する
onlike in this one これとは違って
obtain B from A AからBを得る
elsewhre そのほかの場所では、
(a) applicable 適用可能である
enclose 囲む
okay to A Aして大丈夫です。
side effect 副作用
either どちらか一方
parentheses 確固
expantion 拡張
right-justigy 右寄せにする
encapsulate 要約する
compound statement 複合ステートメント
invocation 呼び出し
conditionally 条件的に
discern がわかる。はっきりと認める。
subjectively 主観的に
corresponding 一致する、対応する
preceding 先行する、前述の、上記の、先立つ
abbreviate 略して書く
identifier 識別子
in preference to A Aに勇戦して。 Aよりはむしろ。
overiding 他の全てに優先する
qualifier 修飾語句
suffice 満足させる
know if A is B AがBであるかどうかを知る
whereas であるのに ところが に反して
convention 慣習 しきたり、
elsewhere ほかの場所
relevant a 関連のある
preferably なるべく むしろ 好んで
compelling 強制的な むりやりの
precedent 慣例
either A or B AまたはB A,Bのどちらでも A,Bのいづれかを
preferable より好ましい
line up 整列する
briefly 簡単に
consistency 一貫性
obvioud 明白な
complicate 複雑にする
unary 単項の
binary operator 二項演算子
precedence 先行、上位
obvious 明白な
desire 強く願う
elicit 誘い出す、引き出す
complaint 不平、ぐち
whatever〜 どんな〜でも
compliant with に従う
consistent with 調和して、矛盾しないで
apporoximately ほぼ
diverge 分岐する、離れる
desire 要望
practice 実践
implicit 暗に示す
assume 思い込む
silent on 言及しないで
History is silent on this event. 歴史は、この事件に関しては何も記していない。
brevity 簡潔な
trim 削減する
onlike in this one これとは違って
obtain B from A AからBを得る
elsewhre そのほかの場所では、
(a) applicable 適用可能である
enclose 囲む
okay to A Aして大丈夫です。
side effect 副作用
either どちらか一方
parentheses 確固
expantion 拡張
right-justigy 右寄せにする
encapsulate 要約する
compound statement 複合ステートメント
invocation 呼び出し
conditionally 条件的に
discern がわかる。はっきりと認める。
subjectively 主観的に
corresponding 一致する、対応する
preceding 先行する、前述の、上記の、先立つ
abbreviate 略して書く
identifier 識別子
in preference to A Aに勇戦して。 Aよりはむしろ。
overiding 他の全てに優先する
qualifier 修飾語句
suffice 満足させる
know if A is B AがBであるかどうかを知る
whereas であるのに ところが に反して
convention 慣習 しきたり、
elsewhere ほかの場所
relevant a 関連のある
preferably なるべく むしろ 好んで
compelling 強制的な むりやりの
precedent 慣例
either A or B AまたはB A,Bのどちらでも A,Bのいづれかを
preferable より好ましい
line up 整列する
briefly 簡単に
consistency 一貫性
obvioud 明白な
complicate 複雑にする
unary 単項の
binary operator 二項演算子
precedence 先行、上位
obvious 明白な
desire 強く願う
elicit 誘い出す、引き出す
complaint 不平、ぐち
whatever〜 どんな〜でも
compliant with に従う
consistent with 調和して、矛盾しないで
apporoximately ほぼ
diverge 分岐する、離れる
desire 要望
practice 実践
[FreeBSD] style(9) 難訳箇所について
man style(9) の翻訳で訳すのが難しいと感じた箇所について日本語翻訳マニュアルの訳を見てみます。
1) Be careful to check the examples before assuming that style is silent on an issue.
-> styleがこれらの例について言及していないと決めつける前に、注意して例を確認してください。
assume: 決め付ける
2) All VCS (version control system) revision identification in files obtained form else where should be maintained.
-> 全てのVCS(バージョン官吏システム)リビジョン識別子は、存在すれば維持します。
obtain: 手に入れる
maintain: 維持する、持続する
3) In declarations, do not put any whitespace between asterisks and adjacent tokens, except for tokens that are indentifiers related to types.
-> 宣言の中では、型に関係づけられたトークンを除いて、アスタリスクと隣接したトークンの間には空白文字を置きません。
4) for example you need to know if the typedef is the structure itself or a pointer to the structure.
-> 例えば、typedefが構造体そのものであるか、構造体へのポインタであるのか、あなたか知る必要があります。
A need to know if B.: Aは、Bであるかを知る必要がある。
5) In general code can be considered "new code" when it makes up about 50% or more of the file(s) involved.
-> ファイルの50%以上かそれ以上を巻き込んだ修正の場合は、一般にコードは、”新しいコード"とみなすことができます。
involve: 巻き込む
6) ANSI C says that such declarations have file scope regardless of the nesting of the declaration.
-> ANSI Cによるとこの様な宣言は、宣言のネスティングによらず、ファイルスコープになります。
regardless of A: Aにもかかららず
7) Code that is approximately FreeBSD KNF style compliant in the repository must not diverse from compliance.
-> リポジトリの中のおおよそFreeBSD KNF style に適合しているコードは、この適合から離れてはなりません。
compliant: 準拠している
diverse: 別種の、異なった
1) Be careful to check the examples before assuming that style is silent on an issue.
-> styleがこれらの例について言及していないと決めつける前に、注意して例を確認してください。
assume: 決め付ける
2) All VCS (version control system) revision identification in files obtained form else where should be maintained.
-> 全てのVCS(バージョン官吏システム)リビジョン識別子は、存在すれば維持します。
obtain: 手に入れる
maintain: 維持する、持続する
3) In declarations, do not put any whitespace between asterisks and adjacent tokens, except for tokens that are indentifiers related to types.
-> 宣言の中では、型に関係づけられたトークンを除いて、アスタリスクと隣接したトークンの間には空白文字を置きません。
4) for example you need to know if the typedef is the structure itself or a pointer to the structure.
-> 例えば、typedefが構造体そのものであるか、構造体へのポインタであるのか、あなたか知る必要があります。
A need to know if B.: Aは、Bであるかを知る必要がある。
5) In general code can be considered "new code" when it makes up about 50% or more of the file(s) involved.
-> ファイルの50%以上かそれ以上を巻き込んだ修正の場合は、一般にコードは、”新しいコード"とみなすことができます。
involve: 巻き込む
6) ANSI C says that such declarations have file scope regardless of the nesting of the declaration.
-> ANSI Cによるとこの様な宣言は、宣言のネスティングによらず、ファイルスコープになります。
regardless of A: Aにもかかららず
7) Code that is approximately FreeBSD KNF style compliant in the repository must not diverse from compliance.
-> リポジトリの中のおおよそFreeBSD KNF style に適合しているコードは、この適合から離れてはなりません。
compliant: 準拠している
diverse: 別種の、異なった
2013年10月15日火曜日
[FreeBSD] styleの自力和訳
英語の鍛錬のためにstyle(9)を自力で英訳してみた。
FreeBSD カーネル開発者用マニュアル
#NAME#
style -- カーネルソースファイル書式ガイド
#DESCRIPTION#
このファイルでは、FreeBSDソース群の中でもカーネルソースファイルの推奨される
書式を規定している。またこれは、ユーザー向けのプログラムのコードの書式
ガイドでもある。多くの書式規則が例文とともに示されている。その書式が
重要な点について記していないと思う前によく例をチェックされい。
/*
* FreeBSDの書式ガイド。CSRGのカーネル標準書式(KNF)に基づいた。
* @(#)style 1.14 (Barkeley) 4/28/95
* $FreeBSD release/9.1.0/share/man.style.9 217807 2011-01-07 08:34:12Z trasz $
*/
/*
* "とても"重要な1行のコメントは、この様に書く。
*/
/*
* 複数行のコメントは、この様に書く。普通の文章と同じように。普通の文章の
* 段落分けと同じように記述する。
*/
著作権の表示は、複数行であるべきだ。一行目は、アスタリスクの後にダッシュを続け
次の様に書く。
/*-
* Copyright (c) 1982-2025 John Q. Public
* All rights reserved.
*
* 長く退屈なライセンスは、ここに書く。しかし、完結かつ短く。
*/
スクリプトは、ソースツリーから"/*-"から始まるコメントの全てをライセンス情報として収集する。
もし、indent(1)の1文字目から始まるライセンスや著作権表示ではないコメントを再整形しないフラグ
を立てることを望む場合は、そのコメントのダッシュをアスタリスクに変更せよ。1行目以外の
コメントは、ライセンス文として考慮されない。
著作権ヘッダーの後に、空行を入れる。そして、C/C++以外のソースファイルのための$FreeBSD$。
バージョンコントロールIDタグ一つのファイルに1つのみ含まれるべきである(これとは違い)。
C/C++以外のソースファイルは、上記の例の様にあるべきである。C/C++のソースファイルにおいては、
以下の1つに準拠する。ファイルの全てのVCS(Version control system) の版は、
その他のファイルでは、メンテナンスされ、含まれ、適用可能で、複数のIDがファイルの履歴を
示す。総じて、外部のIDとインフラを編集すべきではない。ラップされることなしに("#if
defined(#LIBC_SOCS)")、非互換のビットを隠し、IDをオブジェクト
ファイルに含ませないために"#if 0... #nedif"で囲む。ファイル名が変更された
場合、外部のVCSIDの直前にのみ"From: "を追加する。
#if 0
#ifndef lint
static char sccsid[] = "@(#)style 1.14 (Barkeley) 4/28/95":
#endif /* not lint */
#endif
#include <sys/cdefs.h>
__FBSID("#FreeBSD: release/9.1.0/share/man/man9/style.9 217087 2011-01-07 08:34:12Z trasz $"):
ヘッダーファイルの前のその他の空行は、そのままにしておく。
通常は、カーネルのインクルードファイル(例: sys/*.h)が最初に来る。
<sys/types.hと<sys/param.h>の両方ではなく、どちらか一方をインクルードする。
<sys/types.h>は<sys/coefs.h>インクルードする。そして、<sys/types.h>は、
<sys/coefs.h>に依存して問題ない。
#include <sys/types.h> /* ローカルではないインクルードは、<>で囲む */
ネットワークプログラムにおいては、次にネットワーク関係のインクルードファイルを次に書く。
#include <net/if.h>
#include <net/if_dl.H>
#include <net/route.h>
#include <netinet/in.h>
#include <[protocolos/wrhod.h>
カーネルのソースに/usr/includeにあるファイルを使ってはいけない。
次のグループの前に空行を置く。/usr/includeにあるファイルは、アルファベット順で
ソートされていなければいけない。
#include <stdio.h>
グローバルなパスは、<paths.h>で定義されている。プログラム固有のローカルパスは、
ローカルの"pathnames.h"に記述する。
#include <paths.h>
ユーザー固有のインクルードファイルの前に空行を置く。
#include "pathnames.h" /* ローカルのインクルードファイルは、ダブルクオートでくくる*/
実装名前空間でアプリケーションインターフェースを実装する場合を除いて#define したり名前
を宣言してはいけない。
"unsafe"マクロの名前(副作用を伴う)と内容が明白なマクロの名前は、全て大文字にする。
語句のようなマクロの拡張は、一つのトークンか括弧の外を持つ。#defineと
マクロ名の間には、タブ一つを置く。もしマクロがインライン関数の拡張ならば、関数名は、全て小文字
にする。読みやすくするためにバックスラッシュを右寄せにする。もし、マクロが複合ステートメント
ならば、それをdoループで囲む。そうすればif文の中で安全に使うことができる。文章の終端の
セミコロンは、華奢なプリンターやエディタのパースを簡単にするべくマクロよりむしろ
マクロの呼び出しによっておかれるべきだ。
#define MACRO(x, y) do { \
variable = (x) + (y); \
(y) += 2; \
} while(0)
コードが#ifdefや#ifを使い条件的にコンパイルされる時、マッチする#endifや
#elseに続き、読み手が容易に条件付きコンパイルのコード部分の終わりが
分かるようにコメントを追加するかもしれない。そのコメントは、
(主観的に)当該コード部分が長いと思われる場合、20行を越える場合、#ifdef
のネストが読み手を混乱させる可能性がある場合にのみ用いられるべきである。
例外は、lint(1)の目的のために条件付きコンパイルされない複数のケースのために作られるかもしれ
ない。これは、コンパイルされるコードが少ない場合においてさえそうである。コメントは、
1つのスペースで#endifや#elseと離すべきである。短い条件付きコンパイル部分に対しては、
近接したコメントは、つけるべきではない。
#endifへのコメントは、対応する#if、#fidefと表現を一致させるべきである。#else,#elif
へのコメントは、先行する#if、#elif文と逆の表現とすべきである。コメントにおける、
"defined(FOO)"のような準表現は、"FOO"と略される。コメントの目的は、"#ifndef FOO"は、
"#if !defined(FOO)"として扱われる。
#ifdef KTRACE
#include <sys/ktrace.h>
#endif
#ifdef COMPAT_43
/*A large region here, or other condional code. */
#else /* !COMPAT_43 */
/* Or here. */
#endif /* COMPAT_43 */
#ifndef COMPAT_43
/* Yet another large region here, or other conditional code. */
#else /* COMPAT_43 */
/* Or here */
#endif /* !COMPAT_43 */
プロジェクトは、古いBSDスタイルのu_intxx_t式の整数識別子よりむしろISOIEC 9899:1999
("ISO C99") uintxx_t式の符号無し整数の識別子を使うべくゆっくり動いている。新しい
コードは、後者を使うべきである。そして、もし、他の主要な作業が終わり格別の理由がなければ
そのエリアにある古い様式を、新しい様式に変換すべきである。何もないコミットの様に、ケアは、uintxx_tのみのコミットにすべきである。
列挙型の値は、全て大文字である。
enum enumtype {ONE, TWO} et;
識別子における内側の_アンダースコアの使用は、cammelCaseやTitleCaseにもまして
好まれる。
宣言部においては、トークンが型に関連した識別子である場合を除いて隣接したトークンと
アスタリスクの間にスペースを開けてはいけない。(それら識別子は、基底型の名前、修飾子、
独立して宣言されるものと言うよりむしろtypedefで定義されるものである。)
それら識別子は、スペース一つでアスタリスクと分けなさい。
構造体のメンバを宣言する時、使用する順番、サイズ(大きいものから小さいもの)
、アルファベット順でソートして宣言しなさい。最初のカテゴリは、通常適用されない。
しかし、例外がある。1つのメンバーは、1行で宣言しなさい。可読性を向上させるため
メンバー名をあなたの裁量で1つまたは2つのタブで整列するよう努めなさい。一つのタブは、
少なくともメンバーの90%が揃う場合にのみ使用するべきである。とても長い型に続く
名前は、スペース1つで分離すべきである。
主要な構造体は、構造体が使われるファイルの先頭で宣言するすべきである。
また、構造体が複数のソースで使われる場合は、ヘッダーファイルに分離すべきである。
構造体の使用部と宣言部は、分離すべきであり、ヘッダーファイルで宣言されている
場合は、externすべきである。
struct foo {
struct foo *next; /* List of active foo */
struct mumblue amumble; /* mumble のコメント */
int bar; /* コメントを揃えるように */
strcut verylongtypename *baz /* 2つのタブで揃わない場合 */
};
struct foo *foohead; /* グローバルなfooリストの先頭 */
可能な時は常に、自分でリストを回すのではなくてquese(3)マクロを用いよ。
従って、前述の例は、次の様に書くのが好ましい。
#include <sys/queue.h>
struct foo {
LIST_ENTRY(foo) link; /* fooリストには、queueマクロを用いる */
struct mumble amumble; /* mumbleのコメント */
int bar; /* コメントを揃えるように。 */
struct verylongtypename *baz; /* 2つのタブで揃わない場合 */
};
LIST_HEAD(, foo) foohead; /* グローバルなfooリストの先頭 */
構造体の型にtypedefsを用いるのは、避けなさい。Typedefsは、元の型を適切に
隠さないので、問題を抱えがちである。例えば、typedefが構造体自身もしくは構造体への
ポインターかどうかを知る必要がある。加えてそれらは、正確に1回宣言しなければいけない。
ところが、不完全な構造体の型は、不必要であるにもかかわらず何回も記述することができる。
Typedefsは、独立したヘッダーファイルで用いいるのが難しい。typedefを定義するヘッダーは、
用いられるヘッダーより以前に、用いられるヘッダによって(名前空間の汚染をもたらす)インクルード
されなければいけない。また、それらは、typedefを含むことに対するバックドアでなければいけない。
慣習がtypedefを必要とするとき、その名前は、構造体のタグ名と一致させるべきである。Standard C
もしくはPOSIXで指定されている場合を除いてtypedefの最後を"_t"とするのは避けなさい。
/* 構造体の名前は、タグ名と一緒にせよ */
typedefi struct bar {
int level;
} BAR;
typedef int foo; /* これは、foo */
typedef const long baz; /* これは、baz */
全ての関数は、どこかでプロトタイプ宣言されている。
(ほかの場所から使われない)プライベートな関数のプロトタイプ宣言は、ソースコードの
一番最初に持っていくべきである。ソースコード内のみで使われる関数は、staticと
宣言すべきである。
カーネルの別の部分から使われる関数は、関連のあるインクルードファイルでプロトタイプ宣言される。
関数のプロトタイプ宣言は、論理的順序で列挙するべきである。他の順番を使う
明白な理由がない場合は、なるべく、アルファベット順を使うべきである。
一つ以上のモジュールから使用されるローカルな関数は、"extern.h"のような別のヘッダーファイルに
含めるべきである。
__Pマクロを用いるべからず。
総じて、50%以上ファイルが影響を受けるコードは、"新しいコード"と認識される。これは、
既存のコードの慣例を崩すのに十分である。現在のstyleガイドラインに従いなさい。
カーネルは、パラメータの型にに関連付けられた名前を持つ。以下カーネルでの使用例。
void function(int fd);
ヘッダーファイルにおいては、ユーザーランドのアプリケーションに対して見えるようにせよ。
見えるプロトタイプ宣言は、(アンダーバーから始まる)"protected"な名前か名前のない型のどちらか
を用いなければいけない。purotectedな名前を使う方が好まれる。
void function(int);
か
void function(int _fd);
プロトタイプ宣言は、関数の名前を揃えるためにタブの後に多くのスペースを含むかもしれない。
static char *function(int _argc, const char *_arg2, struct foo *_arg3,
struct bar *_arg4);
static void *usage(void);
/*
* 全ての主要なルーチンには、何をするかということを簡単に説明したコメントをつけるべきである。
* mainルーチンの前のコメントは、このプログラムが何をするかを説明すべきである。
*/
int
main(int argc, char *argv[])
{
char *ep;
long num;
int ch;
一貫性のために、オプションをパースするときは、getopt(3)を用いるべきである。
オプションは、switch文の一連の流れの一部ではなく、getopt(3)の呼び出しとswitch文の中で
ソートされるできである。switch文の中の要素であるcascadeには、FALLTHROUGHコメントを
つけるべきである。数の引数に対しては、精度をチェックすべきである。明白な理由に到達不可能な
コードは、/* NOTREACHED */とマークされるかもしれない。
while((ch = getopt(arc, argv, "abNn:")) != -1)
switch (ch) { /* switch文をインデントせよ */
case 'a': /* case文はインデントしない */
aflag = 1; /* case文本体は、1つのタブでインデント */
/* FALLTHROUGH */
case 'b':
bflag = 1;
break;
case 'N':
Nflag = 1l
break;
case 'n':
num = strtol(optarg, &ep, 10);
if (num<= 0 || *ep != '\0') {
warnx("illegal number, -n argument -- %s",
optarg);
usage();
}
break;
case '?':
default:
usage();
}
argc -= optind;
argv += optind;
(if, while, for, return, switch)の後には、スペースをいれよ。ステートメントが
一行以上になる許される場合の除いてゼロもしくは1ステートメントと共にブレース("{""}")を
ステートメントを制御するために用いてはいけない。無限ループは、whileではなく、forを用いよ。
for (p = buf; *p != '\0'; ++p)
/* nothing */
for (; :)
stmt;
for (; :) {
z = a + really + long + statement + that + needs +
two + lines + gets + indented + for + spaces +
on + the + second + and + subsequent + lines;
}
for (; ;) {
if (cond)
stmt;
}
if (val != NULL)
val = realloc(val, newsize);
forループの一部は、空になるかもしれない。ルーチンが特殊で複雑な場合を除いてブロック内で
宣言をしてはいけない。
for (; cnt < 15l cnt++) {
stmt1;
stmt2;
}
インデントは、8文字のタブにすること。2段目のインデントは、4つのスペースにすること。もし、
長いステートメントとなる場合は、演算子を行の最後に書くこと。
while (cnt < 20 && this_variable_name_is_too_long &&
ep != NULL)
z = a + really + long + statement + that + needs +
two + lines + gets + indented + four + spaces +
on + the + second + and + subsequent + lines;
行末に空白を入れては、いけない。タブは、空白の後ろにインデントを揃えるためにのみ使いなさい。
タブよりも多くのスペースを使ってはいけない。タブの前にスペースを入れてはいけない。
ブロックの始まりと終わりのブレースは、elseと同じ行に書きなさい。不必要なブレースは、
いれない。
if (test)
stmt;
else if (bar) {
stmt;
} else
stmt;
関数名の後にスペースを入れない。コンマの後には、スペースを入れよ。'('や'["の後に
スペースを入れない。')'や']'の前にスペースを入れない。
error = function(a1, a2);
if (error != 0)
exit(error);
単項演算子にスペースは、必要ない。二項演算子には、スペースが必要である。優先させる必要がある
場合や複雑なステートメントの場合を除いて()を使ってはいけない。他人は、自分より
混乱しやすいかもしれないということを覚えておこう。下記のコードが理解できるか?
a = b->c[0] + ~b == (e || f) || g && h ? i : j >>1;
k = !(l & FLAGS);
処理に成功した場合は、0を返し、失敗した場合は、1を返せ。
exit(0); /*
* "処理成功時は、0を返す"の様な
* 明白なコメントは、避けよ。
*/
}
関数の返り値の型は、"function"の前の行に書きなさい。関数の中身を書くための右ブレースは、
1行に書きなさい。
satic char *
function(int a1, int a2, float fl, int a4)
{
関数内で変数を宣言する時、サイズ順->アルファベット順で宣言しなさい。複数の変数を
1行でまとめて宣言するのは、OK。もし、一つの型の変数が1行に収まらない時は、複数行に
分けて、型名を行頭に書きなさい。宣言部で変数を初期化することによってコードが
分かりにくくなることのない様に気を付けなさい。このことについては、あまりシビアに
ならなくても良い。初期化部において関数の呼び出しをしてはいけない。
struct foo one, *two;
double three;
int *four, five;
char *six, seven, eight, nine, ten, elven, twelve;
for = myfunction();
関数の中で関数を宣言しては、いけない。ANSI Cにおいては、そのような
不注意な入れ子の宣言は、ファイルスコープを持つ。ローカルスコープに現れる
ファイルスコープは、思わぬ不平を良いコンパイラから引き出す。
キャストとsizeofの後にスペースを入れては、いけない。ちなみに、indent(1)は、
このルールに依らない。sizeofは、丸括弧とともにかかれる。sizeof(var)インスタンスに
冗長な丸括弧のルールを適用しては、いけない。
NULLは、空のポインタ定数を好む。アサイメント等コンパイラが型を知っているコンテキストにおい
ては、(type *)0や(type *)NULLの代わりにNULLを使え。その他のコンテキスト、特に全ての関数の
引数においては、(type *)NULLを使え。(もし、関数のプロトタイプ宣言がスコープにない場合、キャ
ストは、可変長引数においては必要であるが、その他の引数に対しては、不必要である。)
ポインタのNULLチェックの例
(p=f()) == NULL
悪い例:
!(p = f())
論理型でないにもかかわらず、チェックに!を使うな。次の様にすべきである。
IF (*p == '\0')
悪い例:
if (!*p)
void *を返すルーチンは、返り値を勝手にキャストして返してはいけない。
return文における値は、丸括弧で囲むべきである。
err(3)やwarn(3)を使え。自分で実装するな。
if ((four = malloc(sizeof(struct foo))) === NULL)
err(1, (char *)NULL);
if ((six = (int *)overflow()) == NULL)
errx(1, "number overflowwed")'
return (eight);
}
この様な古い様式の関数宣言。
static char *
function(a1, a2, f1, a4)
int a1, a2; /* 整数型の宣言。これらをデフォルトにしてはいけない。*/
float f1; /* floatとdoubleのプロトタイプの違いに注意せよ。 */
int a4; /* 順番が宣言されたリスト */
{
明白にK&Rとの互換性が必要な場合を除いて、ANSIの関数宣言を使いなさい。長いパラメータの
リストは、4つの普通のスペースでインデントしなさい。
可変長の引数は、次の様にすべきである。
#include <stdarg.h>
void
vaf(const char *fmt, ...)
{
vs_list ap;
va_start(ap, fmt);
STUFF;
vs_end(ap);
/* void型を返す関数においては、return文は不要である */
}
static void
usage()
{
/* 関数に、ローカル変数がない場合は、空行を入れる。 */
どんなにそれが、早くきれいだとしても、おろかなバグに気を使わなくても良いように
fputs(3),puts(3),putchar(3)ではなくて、printf(3)を使いなさい。
Usage文は、マニュアルページのSYNOPSISのようにあるべきである。そして、
下記順番になっているべきである。
1. オペラントの必要ないオプションを一番最初仁1組のラケット"[]"の内側にアルファベット順
で書く。
2. オペランドが必要なオプションを次に、同じくアルファベット順でブラケットの内側に書く。
3. 必要な引数があれば、次にコマンドラインで指定すべき順序で書く。
4. 最後に、残りの任意の引数をブラケットの内側に同じくコマンドラインで指定すべき
順序で列挙する。
バーは、"どちらか一方の"オプション、引数を分離する。共に指定すべき複数のオプション、引数は、
一組のブラケットの内側に書く。
"usage: f [-aDde] [-b b_arg] -m m_arg] req1 req2 [opt1 [opt2]]\n"
"usage: f [-a | -b] [-c [-dEe] [-n number]]\n"
(void)fprintf(stderr, "usage" f [ab]\n");
exit(1);
}
マニュアルのオプションの説明は、純粋にアルファベット順であるべきだ。これは、オプションが
引数を取る/取らないにかかわらない。また、大文字小文字の順で示すべきだ。
現在、カーネルコードは、styleガイドに従うべきである。サードパーティによるモジュールや
ディバイスドライバのガイドラインは、より緩和的である。しかし、最低限内面的に
それらのstyleと矛盾しないようにすべきである。
様式的な変化(空白の変化も含め)は、ソースリポジトリにとって重大であり、良い理由を除いて
避けなければいけない。リポジトリにおけるFreeBSD KNF style規則のコードは、コンプライアンス
から逸脱してはいけない。可能な時は、いつでもコードをコードチェッカー(lint(1)やgcc -Wall
にかけ、警告を最小限に減らすべきである。
#SEE ALSO#
indent(1), lint(1), err(3), warn(3), style.Makefile(5)
#HISTORY#
このマニュアルページのほとんどは、4.4BSD-Lite2 release の src/admin/style/styleの
ファイルに基づき、日々の更新は、現在のFreeBSDプロジェクトの要望と実践に反映されている。
src/admin/style/style は、Ken ThompsonとDenis RitchieのAT&T UNIX Version 6に
おけるプログラミング様式のCSRGである。
FreeBSD カーネル開発者用マニュアル
#NAME#
style -- カーネルソースファイル書式ガイド
#DESCRIPTION#
このファイルでは、FreeBSDソース群の中でもカーネルソースファイルの推奨される
書式を規定している。またこれは、ユーザー向けのプログラムのコードの書式
ガイドでもある。多くの書式規則が例文とともに示されている。その書式が
重要な点について記していないと思う前によく例をチェックされい。
/*
* FreeBSDの書式ガイド。CSRGのカーネル標準書式(KNF)に基づいた。
* @(#)style 1.14 (Barkeley) 4/28/95
* $FreeBSD release/9.1.0/share/man.style.9 217807 2011-01-07 08:34:12Z trasz $
*/
/*
* "とても"重要な1行のコメントは、この様に書く。
*/
/*
* 複数行のコメントは、この様に書く。普通の文章と同じように。普通の文章の
* 段落分けと同じように記述する。
*/
著作権の表示は、複数行であるべきだ。一行目は、アスタリスクの後にダッシュを続け
次の様に書く。
/*-
* Copyright (c) 1982-2025 John Q. Public
* All rights reserved.
*
* 長く退屈なライセンスは、ここに書く。しかし、完結かつ短く。
*/
スクリプトは、ソースツリーから"/*-"から始まるコメントの全てをライセンス情報として収集する。
もし、indent(1)の1文字目から始まるライセンスや著作権表示ではないコメントを再整形しないフラグ
を立てることを望む場合は、そのコメントのダッシュをアスタリスクに変更せよ。1行目以外の
コメントは、ライセンス文として考慮されない。
著作権ヘッダーの後に、空行を入れる。そして、C/C++以外のソースファイルのための$FreeBSD$。
バージョンコントロールIDタグ一つのファイルに1つのみ含まれるべきである(これとは違い)。
C/C++以外のソースファイルは、上記の例の様にあるべきである。C/C++のソースファイルにおいては、
以下の1つに準拠する。ファイルの全てのVCS(Version control system) の版は、
その他のファイルでは、メンテナンスされ、含まれ、適用可能で、複数のIDがファイルの履歴を
示す。総じて、外部のIDとインフラを編集すべきではない。ラップされることなしに("#if
defined(#LIBC_SOCS)")、非互換のビットを隠し、IDをオブジェクト
ファイルに含ませないために"#if 0... #nedif"で囲む。ファイル名が変更された
場合、外部のVCSIDの直前にのみ"From: "を追加する。
#if 0
#ifndef lint
static char sccsid[] = "@(#)style 1.14 (Barkeley) 4/28/95":
#endif /* not lint */
#endif
#include <sys/cdefs.h>
__FBSID("#FreeBSD: release/9.1.0/share/man/man9/style.9 217087 2011-01-07 08:34:12Z trasz $"):
ヘッダーファイルの前のその他の空行は、そのままにしておく。
通常は、カーネルのインクルードファイル(例: sys/*.h)が最初に来る。
<sys/types.hと<sys/param.h>の両方ではなく、どちらか一方をインクルードする。
<sys/types.h>は<sys/coefs.h>インクルードする。そして、<sys/types.h>は、
<sys/coefs.h>に依存して問題ない。
#include <sys/types.h> /* ローカルではないインクルードは、<>で囲む */
ネットワークプログラムにおいては、次にネットワーク関係のインクルードファイルを次に書く。
#include <net/if.h>
#include <net/if_dl.H>
#include <net/route.h>
#include <netinet/in.h>
#include <[protocolos/wrhod.h>
カーネルのソースに/usr/includeにあるファイルを使ってはいけない。
次のグループの前に空行を置く。/usr/includeにあるファイルは、アルファベット順で
ソートされていなければいけない。
#include <stdio.h>
グローバルなパスは、<paths.h>で定義されている。プログラム固有のローカルパスは、
ローカルの"pathnames.h"に記述する。
#include <paths.h>
ユーザー固有のインクルードファイルの前に空行を置く。
#include "pathnames.h" /* ローカルのインクルードファイルは、ダブルクオートでくくる*/
実装名前空間でアプリケーションインターフェースを実装する場合を除いて#define したり名前
を宣言してはいけない。
"unsafe"マクロの名前(副作用を伴う)と内容が明白なマクロの名前は、全て大文字にする。
語句のようなマクロの拡張は、一つのトークンか括弧の外を持つ。#defineと
マクロ名の間には、タブ一つを置く。もしマクロがインライン関数の拡張ならば、関数名は、全て小文字
にする。読みやすくするためにバックスラッシュを右寄せにする。もし、マクロが複合ステートメント
ならば、それをdoループで囲む。そうすればif文の中で安全に使うことができる。文章の終端の
セミコロンは、華奢なプリンターやエディタのパースを簡単にするべくマクロよりむしろ
マクロの呼び出しによっておかれるべきだ。
#define MACRO(x, y) do { \
variable = (x) + (y); \
(y) += 2; \
} while(0)
コードが#ifdefや#ifを使い条件的にコンパイルされる時、マッチする#endifや
#elseに続き、読み手が容易に条件付きコンパイルのコード部分の終わりが
分かるようにコメントを追加するかもしれない。そのコメントは、
(主観的に)当該コード部分が長いと思われる場合、20行を越える場合、#ifdef
のネストが読み手を混乱させる可能性がある場合にのみ用いられるべきである。
例外は、lint(1)の目的のために条件付きコンパイルされない複数のケースのために作られるかもしれ
ない。これは、コンパイルされるコードが少ない場合においてさえそうである。コメントは、
1つのスペースで#endifや#elseと離すべきである。短い条件付きコンパイル部分に対しては、
近接したコメントは、つけるべきではない。
#endifへのコメントは、対応する#if、#fidefと表現を一致させるべきである。#else,#elif
へのコメントは、先行する#if、#elif文と逆の表現とすべきである。コメントにおける、
"defined(FOO)"のような準表現は、"FOO"と略される。コメントの目的は、"#ifndef FOO"は、
"#if !defined(FOO)"として扱われる。
#ifdef KTRACE
#include <sys/ktrace.h>
#endif
#ifdef COMPAT_43
/*A large region here, or other condional code. */
#else /* !COMPAT_43 */
/* Or here. */
#endif /* COMPAT_43 */
#ifndef COMPAT_43
/* Yet another large region here, or other conditional code. */
#else /* COMPAT_43 */
/* Or here */
#endif /* !COMPAT_43 */
プロジェクトは、古いBSDスタイルのu_intxx_t式の整数識別子よりむしろISOIEC 9899:1999
("ISO C99") uintxx_t式の符号無し整数の識別子を使うべくゆっくり動いている。新しい
コードは、後者を使うべきである。そして、もし、他の主要な作業が終わり格別の理由がなければ
そのエリアにある古い様式を、新しい様式に変換すべきである。何もないコミットの様に、ケアは、uintxx_tのみのコミットにすべきである。
列挙型の値は、全て大文字である。
enum enumtype {ONE, TWO} et;
識別子における内側の_アンダースコアの使用は、cammelCaseやTitleCaseにもまして
好まれる。
宣言部においては、トークンが型に関連した識別子である場合を除いて隣接したトークンと
アスタリスクの間にスペースを開けてはいけない。(それら識別子は、基底型の名前、修飾子、
独立して宣言されるものと言うよりむしろtypedefで定義されるものである。)
それら識別子は、スペース一つでアスタリスクと分けなさい。
構造体のメンバを宣言する時、使用する順番、サイズ(大きいものから小さいもの)
、アルファベット順でソートして宣言しなさい。最初のカテゴリは、通常適用されない。
しかし、例外がある。1つのメンバーは、1行で宣言しなさい。可読性を向上させるため
メンバー名をあなたの裁量で1つまたは2つのタブで整列するよう努めなさい。一つのタブは、
少なくともメンバーの90%が揃う場合にのみ使用するべきである。とても長い型に続く
名前は、スペース1つで分離すべきである。
主要な構造体は、構造体が使われるファイルの先頭で宣言するすべきである。
また、構造体が複数のソースで使われる場合は、ヘッダーファイルに分離すべきである。
構造体の使用部と宣言部は、分離すべきであり、ヘッダーファイルで宣言されている
場合は、externすべきである。
struct foo {
struct foo *next; /* List of active foo */
struct mumblue amumble; /* mumble のコメント */
int bar; /* コメントを揃えるように */
strcut verylongtypename *baz /* 2つのタブで揃わない場合 */
};
struct foo *foohead; /* グローバルなfooリストの先頭 */
可能な時は常に、自分でリストを回すのではなくてquese(3)マクロを用いよ。
従って、前述の例は、次の様に書くのが好ましい。
#include <sys/queue.h>
struct foo {
LIST_ENTRY(foo) link; /* fooリストには、queueマクロを用いる */
struct mumble amumble; /* mumbleのコメント */
int bar; /* コメントを揃えるように。 */
struct verylongtypename *baz; /* 2つのタブで揃わない場合 */
};
LIST_HEAD(, foo) foohead; /* グローバルなfooリストの先頭 */
構造体の型にtypedefsを用いるのは、避けなさい。Typedefsは、元の型を適切に
隠さないので、問題を抱えがちである。例えば、typedefが構造体自身もしくは構造体への
ポインターかどうかを知る必要がある。加えてそれらは、正確に1回宣言しなければいけない。
ところが、不完全な構造体の型は、不必要であるにもかかわらず何回も記述することができる。
Typedefsは、独立したヘッダーファイルで用いいるのが難しい。typedefを定義するヘッダーは、
用いられるヘッダーより以前に、用いられるヘッダによって(名前空間の汚染をもたらす)インクルード
されなければいけない。また、それらは、typedefを含むことに対するバックドアでなければいけない。
慣習がtypedefを必要とするとき、その名前は、構造体のタグ名と一致させるべきである。Standard C
もしくはPOSIXで指定されている場合を除いてtypedefの最後を"_t"とするのは避けなさい。
/* 構造体の名前は、タグ名と一緒にせよ */
typedefi struct bar {
int level;
} BAR;
typedef int foo; /* これは、foo */
typedef const long baz; /* これは、baz */
全ての関数は、どこかでプロトタイプ宣言されている。
(ほかの場所から使われない)プライベートな関数のプロトタイプ宣言は、ソースコードの
一番最初に持っていくべきである。ソースコード内のみで使われる関数は、staticと
宣言すべきである。
カーネルの別の部分から使われる関数は、関連のあるインクルードファイルでプロトタイプ宣言される。
関数のプロトタイプ宣言は、論理的順序で列挙するべきである。他の順番を使う
明白な理由がない場合は、なるべく、アルファベット順を使うべきである。
一つ以上のモジュールから使用されるローカルな関数は、"extern.h"のような別のヘッダーファイルに
含めるべきである。
__Pマクロを用いるべからず。
総じて、50%以上ファイルが影響を受けるコードは、"新しいコード"と認識される。これは、
既存のコードの慣例を崩すのに十分である。現在のstyleガイドラインに従いなさい。
カーネルは、パラメータの型にに関連付けられた名前を持つ。以下カーネルでの使用例。
void function(int fd);
ヘッダーファイルにおいては、ユーザーランドのアプリケーションに対して見えるようにせよ。
見えるプロトタイプ宣言は、(アンダーバーから始まる)"protected"な名前か名前のない型のどちらか
を用いなければいけない。purotectedな名前を使う方が好まれる。
void function(int);
か
void function(int _fd);
プロトタイプ宣言は、関数の名前を揃えるためにタブの後に多くのスペースを含むかもしれない。
static char *function(int _argc, const char *_arg2, struct foo *_arg3,
struct bar *_arg4);
static void *usage(void);
/*
* 全ての主要なルーチンには、何をするかということを簡単に説明したコメントをつけるべきである。
* mainルーチンの前のコメントは、このプログラムが何をするかを説明すべきである。
*/
int
main(int argc, char *argv[])
{
char *ep;
long num;
int ch;
一貫性のために、オプションをパースするときは、getopt(3)を用いるべきである。
オプションは、switch文の一連の流れの一部ではなく、getopt(3)の呼び出しとswitch文の中で
ソートされるできである。switch文の中の要素であるcascadeには、FALLTHROUGHコメントを
つけるべきである。数の引数に対しては、精度をチェックすべきである。明白な理由に到達不可能な
コードは、/* NOTREACHED */とマークされるかもしれない。
while((ch = getopt(arc, argv, "abNn:")) != -1)
switch (ch) { /* switch文をインデントせよ */
case 'a': /* case文はインデントしない */
aflag = 1; /* case文本体は、1つのタブでインデント */
/* FALLTHROUGH */
case 'b':
bflag = 1;
break;
case 'N':
Nflag = 1l
break;
case 'n':
num = strtol(optarg, &ep, 10);
if (num<= 0 || *ep != '\0') {
warnx("illegal number, -n argument -- %s",
optarg);
usage();
}
break;
case '?':
default:
usage();
}
argc -= optind;
argv += optind;
(if, while, for, return, switch)の後には、スペースをいれよ。ステートメントが
一行以上になる許される場合の除いてゼロもしくは1ステートメントと共にブレース("{""}")を
ステートメントを制御するために用いてはいけない。無限ループは、whileではなく、forを用いよ。
for (p = buf; *p != '\0'; ++p)
/* nothing */
for (; :)
stmt;
for (; :) {
z = a + really + long + statement + that + needs +
two + lines + gets + indented + for + spaces +
on + the + second + and + subsequent + lines;
}
for (; ;) {
if (cond)
stmt;
}
if (val != NULL)
val = realloc(val, newsize);
forループの一部は、空になるかもしれない。ルーチンが特殊で複雑な場合を除いてブロック内で
宣言をしてはいけない。
for (; cnt < 15l cnt++) {
stmt1;
stmt2;
}
インデントは、8文字のタブにすること。2段目のインデントは、4つのスペースにすること。もし、
長いステートメントとなる場合は、演算子を行の最後に書くこと。
while (cnt < 20 && this_variable_name_is_too_long &&
ep != NULL)
z = a + really + long + statement + that + needs +
two + lines + gets + indented + four + spaces +
on + the + second + and + subsequent + lines;
行末に空白を入れては、いけない。タブは、空白の後ろにインデントを揃えるためにのみ使いなさい。
タブよりも多くのスペースを使ってはいけない。タブの前にスペースを入れてはいけない。
ブロックの始まりと終わりのブレースは、elseと同じ行に書きなさい。不必要なブレースは、
いれない。
if (test)
stmt;
else if (bar) {
stmt;
} else
stmt;
関数名の後にスペースを入れない。コンマの後には、スペースを入れよ。'('や'["の後に
スペースを入れない。')'や']'の前にスペースを入れない。
error = function(a1, a2);
if (error != 0)
exit(error);
単項演算子にスペースは、必要ない。二項演算子には、スペースが必要である。優先させる必要がある
場合や複雑なステートメントの場合を除いて()を使ってはいけない。他人は、自分より
混乱しやすいかもしれないということを覚えておこう。下記のコードが理解できるか?
a = b->c[0] + ~b == (e || f) || g && h ? i : j >>1;
k = !(l & FLAGS);
処理に成功した場合は、0を返し、失敗した場合は、1を返せ。
exit(0); /*
* "処理成功時は、0を返す"の様な
* 明白なコメントは、避けよ。
*/
}
関数の返り値の型は、"function"の前の行に書きなさい。関数の中身を書くための右ブレースは、
1行に書きなさい。
satic char *
function(int a1, int a2, float fl, int a4)
{
関数内で変数を宣言する時、サイズ順->アルファベット順で宣言しなさい。複数の変数を
1行でまとめて宣言するのは、OK。もし、一つの型の変数が1行に収まらない時は、複数行に
分けて、型名を行頭に書きなさい。宣言部で変数を初期化することによってコードが
分かりにくくなることのない様に気を付けなさい。このことについては、あまりシビアに
ならなくても良い。初期化部において関数の呼び出しをしてはいけない。
struct foo one, *two;
double three;
int *four, five;
char *six, seven, eight, nine, ten, elven, twelve;
for = myfunction();
関数の中で関数を宣言しては、いけない。ANSI Cにおいては、そのような
不注意な入れ子の宣言は、ファイルスコープを持つ。ローカルスコープに現れる
ファイルスコープは、思わぬ不平を良いコンパイラから引き出す。
キャストとsizeofの後にスペースを入れては、いけない。ちなみに、indent(1)は、
このルールに依らない。sizeofは、丸括弧とともにかかれる。sizeof(var)インスタンスに
冗長な丸括弧のルールを適用しては、いけない。
NULLは、空のポインタ定数を好む。アサイメント等コンパイラが型を知っているコンテキストにおい
ては、(type *)0や(type *)NULLの代わりにNULLを使え。その他のコンテキスト、特に全ての関数の
引数においては、(type *)NULLを使え。(もし、関数のプロトタイプ宣言がスコープにない場合、キャ
ストは、可変長引数においては必要であるが、その他の引数に対しては、不必要である。)
ポインタのNULLチェックの例
(p=f()) == NULL
悪い例:
!(p = f())
論理型でないにもかかわらず、チェックに!を使うな。次の様にすべきである。
IF (*p == '\0')
悪い例:
if (!*p)
void *を返すルーチンは、返り値を勝手にキャストして返してはいけない。
return文における値は、丸括弧で囲むべきである。
err(3)やwarn(3)を使え。自分で実装するな。
if ((four = malloc(sizeof(struct foo))) === NULL)
err(1, (char *)NULL);
if ((six = (int *)overflow()) == NULL)
errx(1, "number overflowwed")'
return (eight);
}
この様な古い様式の関数宣言。
static char *
function(a1, a2, f1, a4)
int a1, a2; /* 整数型の宣言。これらをデフォルトにしてはいけない。*/
float f1; /* floatとdoubleのプロトタイプの違いに注意せよ。 */
int a4; /* 順番が宣言されたリスト */
{
明白にK&Rとの互換性が必要な場合を除いて、ANSIの関数宣言を使いなさい。長いパラメータの
リストは、4つの普通のスペースでインデントしなさい。
可変長の引数は、次の様にすべきである。
#include <stdarg.h>
void
vaf(const char *fmt, ...)
{
vs_list ap;
va_start(ap, fmt);
STUFF;
vs_end(ap);
/* void型を返す関数においては、return文は不要である */
}
static void
usage()
{
/* 関数に、ローカル変数がない場合は、空行を入れる。 */
どんなにそれが、早くきれいだとしても、おろかなバグに気を使わなくても良いように
fputs(3),puts(3),putchar(3)ではなくて、printf(3)を使いなさい。
Usage文は、マニュアルページのSYNOPSISのようにあるべきである。そして、
下記順番になっているべきである。
1. オペラントの必要ないオプションを一番最初仁1組のラケット"[]"の内側にアルファベット順
で書く。
2. オペランドが必要なオプションを次に、同じくアルファベット順でブラケットの内側に書く。
3. 必要な引数があれば、次にコマンドラインで指定すべき順序で書く。
4. 最後に、残りの任意の引数をブラケットの内側に同じくコマンドラインで指定すべき
順序で列挙する。
バーは、"どちらか一方の"オプション、引数を分離する。共に指定すべき複数のオプション、引数は、
一組のブラケットの内側に書く。
"usage: f [-aDde] [-b b_arg] -m m_arg] req1 req2 [opt1 [opt2]]\n"
"usage: f [-a | -b] [-c [-dEe] [-n number]]\n"
(void)fprintf(stderr, "usage" f [ab]\n");
exit(1);
}
マニュアルのオプションの説明は、純粋にアルファベット順であるべきだ。これは、オプションが
引数を取る/取らないにかかわらない。また、大文字小文字の順で示すべきだ。
現在、カーネルコードは、styleガイドに従うべきである。サードパーティによるモジュールや
ディバイスドライバのガイドラインは、より緩和的である。しかし、最低限内面的に
それらのstyleと矛盾しないようにすべきである。
様式的な変化(空白の変化も含め)は、ソースリポジトリにとって重大であり、良い理由を除いて
避けなければいけない。リポジトリにおけるFreeBSD KNF style規則のコードは、コンプライアンス
から逸脱してはいけない。可能な時は、いつでもコードをコードチェッカー(lint(1)やgcc -Wall
にかけ、警告を最小限に減らすべきである。
#SEE ALSO#
indent(1), lint(1), err(3), warn(3), style.Makefile(5)
#HISTORY#
このマニュアルページのほとんどは、4.4BSD-Lite2 release の src/admin/style/styleの
ファイルに基づき、日々の更新は、現在のFreeBSDプロジェクトの要望と実践に反映されている。
src/admin/style/style は、Ken ThompsonとDenis RitchieのAT&T UNIX Version 6に
おけるプログラミング様式のCSRGである。
2013年9月28日土曜日
[xfce] uim-anthy-gtk-systray をログイン時に実行
表記の件について
[Applications Menu - Settings - Session and Startup] をクリック。
「Seccion and Startup」ダイアログの「Application Auotstart」タブを選択して。
「uim-toolbar-gtk-systray」を追加します。
ちなみに、設定ファイル弄る方法を初め模索しましたが「uim-toolbar-gtk-systray」が実行されるタイミングが悪く(ファイルの編集方法が悪く)諦めました。
[Applications Menu - Settings - Session and Startup] をクリック。
「Seccion and Startup」ダイアログの「Application Auotstart」タブを選択して。
「uim-toolbar-gtk-systray」を追加します。
ちなみに、設定ファイル弄る方法を初め模索しましたが「uim-toolbar-gtk-systray」が実行されるタイミングが悪く(ファイルの編集方法が悪く)諦めました。
2013年9月24日火曜日
[FreeBSD] Installing flash plugin
Environmente: FreeBSD 9.1-RELEASE
If you installed emulators/linux_base-f10
You only to run
kldload linux
And add following line to /etc/rc.conf
linux_enable="YES"
And reference
7.2.1.2. Firefox and Adobe® Flash™ Plugin
If you installed emulators/linux_base-f10
You only to run
kldload linux
And add following line to /etc/rc.conf
linux_enable="YES"
And reference
7.2.1.2. Firefox and Adobe® Flash™ Plugin
[FreeBSD] compiling chromium browser
I compiled chromium browser(Version 29.0.1547.76) on FreeBSD 9.1-RELEASE.
[Point of compiling chromium browser]
compile with out debug symbol
When I compiled chromium with debug symbol. chrome aborted by signal 16.
$ cd /usr/ports/www/chromium/
$ make config-recursive
$ make
$ make install
And add follwoing line to /etc/syctl.conf
kern.ipc.shm_allow_removed=1
So you can run chromium browser.
$ chrome # not chromium
[Point of compiling chromium browser]
compile with out debug symbol
When I compiled chromium with debug symbol. chrome aborted by signal 16.
$ cd /usr/ports/www/chromium/
$ make config-recursive
$ make
$ make install
And add follwoing line to /etc/syctl.conf
kern.ipc.shm_allow_removed=1
So you can run chromium browser.
$ chrome # not chromium
2013年9月23日月曜日
[Office Suite] docx pptx xlsx について
「docx pptx xlsx」という一連の「*x」というフォーマットは、zipでxmlファイル群圧縮しているらしい。
PyCon 2013 の kzfmさんの資料を参考にさせて頂き実践してみた。
まず、サンプルのパワーポイントスライドを作って「sample.pptx」で保存する。

そして、sample.pptxを解凍する。
$ unzip sample.pptx
解凍すると下記のようなファイルが出てくる。
その中の「ppt/slides/slide1.xml」がスライドの内容となるので、適当なエディタで編集する。

再びZipで圧縮して、「after.pptx」とする。
$ zip -r after.pptx \[Content_Types].xml docProps/ ppt/ _rels/
Power Pointで圧縮したafter.pptxを開いてみる。

[pptxを解凍して出てきたファイル群]
$ tree
|-- [Content_Types].xml
|-- _rels
|-- docProps
| |-- app.xml
| |-- core.xml
| `-- thumbnail.jpeg
|-- file.lst
|-- ppt
| |-- _rels
| | `-- presentation.xml.rels
| |-- presProps.xml
| |-- presentation.xml
| |-- slideLayouts
| | |-- _rels
| | | |-- slideLayout1.xml.rels
| | | |-- slideLayout10.xml.rels
| | | |-- slideLayout11.xml.rels
| | | |-- slideLayout2.xml.rels
| | | |-- slideLayout3.xml.rels
| | | |-- slideLayout4.xml.rels
| | | |-- slideLayout5.xml.rels
| | | |-- slideLayout6.xml.rels
| | | |-- slideLayout7.xml.rels
| | | |-- slideLayout8.xml.rels
| | | `-- slideLayout9.xml.rels
| | |-- slideLayout1.xml
| | |-- slideLayout10.xml
| | |-- slideLayout11.xml
| | |-- slideLayout2.xml
| | |-- slideLayout3.xml
| | |-- slideLayout4.xml
| | |-- slideLayout5.xml
| | |-- slideLayout6.xml
| | |-- slideLayout7.xml
| | |-- slideLayout8.xml
| | `-- slideLayout9.xml
| |-- slideMasters
| | |-- _rels
| | | `-- slideMaster1.xml.rels
| | `-- slideMaster1.xml
| |-- slides
| | |-- _rels
| | | `-- slide1.xml.rels
| | `-- slide1.xml
| |-- tableStyles.xml
| |-- theme
| | `-- theme1.xml
| `-- viewProps.xml
`-- sample.pptx
11 directories, 38 files
PyCon 2013 の kzfmさんの資料を参考にさせて頂き実践してみた。
まず、サンプルのパワーポイントスライドを作って「sample.pptx」で保存する。

そして、sample.pptxを解凍する。
$ unzip sample.pptx
解凍すると下記のようなファイルが出てくる。
その中の「ppt/slides/slide1.xml」がスライドの内容となるので、適当なエディタで編集する。

再びZipで圧縮して、「after.pptx」とする。
$ zip -r after.pptx \[Content_Types].xml docProps/ ppt/ _rels/
Power Pointで圧縮したafter.pptxを開いてみる。

[pptxを解凍して出てきたファイル群]
$ tree
|-- [Content_Types].xml
|-- _rels
|-- docProps
| |-- app.xml
| |-- core.xml
| `-- thumbnail.jpeg
|-- file.lst
|-- ppt
| |-- _rels
| | `-- presentation.xml.rels
| |-- presProps.xml
| |-- presentation.xml
| |-- slideLayouts
| | |-- _rels
| | | |-- slideLayout1.xml.rels
| | | |-- slideLayout10.xml.rels
| | | |-- slideLayout11.xml.rels
| | | |-- slideLayout2.xml.rels
| | | |-- slideLayout3.xml.rels
| | | |-- slideLayout4.xml.rels
| | | |-- slideLayout5.xml.rels
| | | |-- slideLayout6.xml.rels
| | | |-- slideLayout7.xml.rels
| | | |-- slideLayout8.xml.rels
| | | `-- slideLayout9.xml.rels
| | |-- slideLayout1.xml
| | |-- slideLayout10.xml
| | |-- slideLayout11.xml
| | |-- slideLayout2.xml
| | |-- slideLayout3.xml
| | |-- slideLayout4.xml
| | |-- slideLayout5.xml
| | |-- slideLayout6.xml
| | |-- slideLayout7.xml
| | |-- slideLayout8.xml
| | `-- slideLayout9.xml
| |-- slideMasters
| | |-- _rels
| | | `-- slideMaster1.xml.rels
| | `-- slideMaster1.xml
| |-- slides
| | |-- _rels
| | | `-- slide1.xml.rels
| | `-- slide1.xml
| |-- tableStyles.xml
| |-- theme
| | `-- theme1.xml
| `-- viewProps.xml
`-- sample.pptx
11 directories, 38 files
[D3] SVG Path
D3を用いたSVGのPathの描画
ソースは、こちら
ソースは、こちら
Path.prototype = {
constructor: Path,
readNodesData: function()
{
this.lineNodes = [
{"x": 1, "y": 5}, {"x": 20, "y": 20},
{"x": 40, "y": 10}, {"x": 60, "y": 40},
{"x": 80, "y": 5}, {"x": 100, "y": 60}
];
return;
}
};
function Path()
{
this.lineNodes;
this.svg = d3.select("#drawArea").append("svg")
.attr("width", 100)
.attr("height", 100);
this.lineFunction = d3.svg.line()
.x(function(d){return d.x;})
.y(function(d){return d.y;})
.interpolate("linear");
this.readNodesData();
this.line = this.svg.append("path")
.attr("d", this.lineFunction(this.lineNodes))
.attr("stroke", "blue")
.attr("stroke-width", 2)
.attr("fill", "none");
return;
}
2013年9月19日木曜日
[Python] Memo about list
記憶の定着を図るためのメモ
#del について
>>> list = [0,1,2]
>>> del list[1]
>>> list
[0, 2]
>>> list [0]
0
>>> list [1]
2
# リストに対する+= 演算子
>>> slots = []
>>> slots += [0,0]
>>> print slots
[0, 0]
>>> slots += [1,1]
>>> print slots
[0, 0, 1, 1]
>>>
#del について
>>> list = [0,1,2]
>>> del list[1]
>>> list
[0, 2]
>>> list [0]
0
>>> list [1]
2
# リストに対する
>>> slots = []
>>> slots += [0,0]
>>> print slots
[0, 0]
>>> slots += [1,1]
>>> print slots
[0, 0, 1, 1]
>>>
2013年9月18日水曜日
[Python] Difference between list and tuple
Python初心者の自分としては、よく分からなかった。
記述方法の違いしか分からなかった。(大括弧囲みか丸カッコ囲みか)
しかし、違いがもう一つわかった。
リスト(List) -> 値の再代入ができる
タプル(Tuple) -> 値の再代入ができない
試しに、、、
>>> vec = [2,4,6]
>>> list = [[x,x*2] for x in vec] # リストの生成
>>> print list
[[2, 4], [4, 8], [6, 12]]
>>> tuple = [(x,x*3) for x in vec] #タプルの生成
>>> print tuple
[(2, 6), (4, 12), (6, 18)]
>>> list[0][1] = 5 # リストに値を再代入してみる
>>> print list
[[2, 5], [4, 8], [6, 12]] #代入できている
>>> tuple[0][1] = 7 #タプルに再代入してみる
Traceback (most recent call last): # タプルは、アイテムのアサインをサポートしていないとおっしゃてる
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> print tuple
[(2, 6), (4, 12), (6, 18)]
>>>
記述方法の違いしか分からなかった。(大括弧囲みか丸カッコ囲みか)
しかし、違いがもう一つわかった。
リスト(List) -> 値の再代入ができる
タプル(Tuple) -> 値の再代入ができない
試しに、、、
>>> vec = [2,4,6]
>>> list = [[x,x*2] for x in vec] # リストの生成
>>> print list
[[2, 4], [4, 8], [6, 12]]
>>> tuple = [(x,x*3) for x in vec] #タプルの生成
>>> print tuple
[(2, 6), (4, 12), (6, 18)]
>>> list[0][1] = 5 # リストに値を再代入してみる
>>> print list
[[2, 5], [4, 8], [6, 12]] #代入できている
>>> tuple[0][1] = 7 #タプルに再代入してみる
Traceback (most recent call last): # タプルは、アイテムのアサインをサポートしていないとおっしゃてる
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> print tuple
[(2, 6), (4, 12), (6, 18)]
>>>
2013年9月16日月曜日
[D3] 事始め
D3 (Data-Driven Documents) を試した。今回の着目点は、
1.SVGに要素を追加
2.追加した要素に読み込んだデータをアサインする data(dataset)
3.アサインしたデータに基づいた要素属性の設定(特に色
4.描画系とデータという異なる座標値を変換する scale
5.軸の追加
参考ページ: http://alignedleft.com/tutorials/d3
上記ページは、D3の概要を知るには、よくまとめられていて大変参考にさせて頂きました。
サンプルついて
散布図の描画をイメージしたものでRunボタンを押すとランダムな位置に大きさの異なる。5つの円が描画されます。円の色については、色のrangeを使って自身の大きさが小さいほど青、大きいほど赤になるようにしています([A])。
Updateボタンを押すとその都度円の位置が変わります([B])。
ソース
ScatterSample.prototype = {
constructor: ScatterSample,
circleFillColor: function(d)
{
var color = d3.scale.linear().domain([0,30]).range(['blue','red']); //[A]
return color(d);
},
mkCirclePosData: function()
{
var random = Math.random();
random = (random - 0.5) * 2.0;
return random;
},
changeCirclesPos: function() // [B]
{
svg = d3.selectAll('svg');
circles = svg.selectAll('circle');
circles.attr("cx", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.xScale(pos);
})
.attr("cy", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.yScale(pos);
})
return;
}
};
function ScatterSample()
{
var dataset = [5, 10, 15, 20, 25];
this.width = 500;
this.height = 300;
ScatterSample.xScale = d3.scale.linear()
.domain([-1, 1])
.range([50, this.width-50]);
ScatterSample.yScale = d3.scale.linear()
.domain([-1, 1])
.range([50, this.height-50]);
var svg = d3.select("#drawArea")
.append("svg") // 1.
.attr("width" , this.width)
.attr("height", this.height);
var circles = svg.selectAll("circle")
.data(dataset) // 2.
.enter()
.append("circle");
circles.attr("cx", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.xScale(pos); // 4.
})
.attr("cy", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.yScale(pos);
})
.attr("r", function(d){
return d;
})
.style("fill", function(d){ // 3.
return ScatterSample.prototype.circleFillColor(d);
});
var yAxis = d3.svg.axis()
.scale(ScatterSample.yScale)
.ticks(5)
.orient("left");
svg.append("g") // 5.
.attr("transform", "translate(50,0)")
.call(yAxis)
.selectAll("path,line")
.attr("fill","none").attr("stroke","black")
.attr("shape-redering","crispEdges");
var xAxis = d3.svg.axis()
.scale(ScatterSample.xScale)
.ticks(5)
.orient("bottom");
svg.append("g")
.attr("transform", "translate(0,250)")
.call(xAxis)
.selectAll("path,line")
.attr("fill","none").attr("stroke","black")
.attr("shape-redering","crispEdges");
}
1.SVGに要素を追加
2.追加した要素に読み込んだデータをアサインする data(dataset)
3.アサインしたデータに基づいた要素属性の設定(特に色
4.描画系とデータという異なる座標値を変換する scale
5.軸の追加
参考ページ: http://alignedleft.com/tutorials/d3
上記ページは、D3の概要を知るには、よくまとめられていて大変参考にさせて頂きました。
サンプルついて
散布図の描画をイメージしたものでRunボタンを押すとランダムな位置に大きさの異なる。5つの円が描画されます。円の色については、色のrangeを使って自身の大きさが小さいほど青、大きいほど赤になるようにしています([A])。
Updateボタンを押すとその都度円の位置が変わります([B])。
ソース
ScatterSample.prototype = {
constructor: ScatterSample,
circleFillColor: function(d)
{
var color = d3.scale.linear().domain([0,30]).range(['blue','red']); //[A]
return color(d);
},
mkCirclePosData: function()
{
var random = Math.random();
random = (random - 0.5) * 2.0;
return random;
},
changeCirclesPos: function() // [B]
{
svg = d3.selectAll('svg');
circles = svg.selectAll('circle');
circles.attr("cx", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.xScale(pos);
})
.attr("cy", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.yScale(pos);
})
return;
}
};
function ScatterSample()
{
var dataset = [5, 10, 15, 20, 25];
this.width = 500;
this.height = 300;
ScatterSample.xScale = d3.scale.linear()
.domain([-1, 1])
.range([50, this.width-50]);
ScatterSample.yScale = d3.scale.linear()
.domain([-1, 1])
.range([50, this.height-50]);
var svg = d3.select("#drawArea")
.append("svg") // 1.
.attr("width" , this.width)
.attr("height", this.height);
var circles = svg.selectAll("circle")
.data(dataset) // 2.
.enter()
.append("circle");
circles.attr("cx", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.xScale(pos); // 4.
})
.attr("cy", function(){
pos = ScatterSample.prototype.mkCirclePosData();
return ScatterSample.yScale(pos);
})
.attr("r", function(d){
return d;
})
.style("fill", function(d){ // 3.
return ScatterSample.prototype.circleFillColor(d);
});
var yAxis = d3.svg.axis()
.scale(ScatterSample.yScale)
.ticks(5)
.orient("left");
svg.append("g") // 5.
.attr("transform", "translate(50,0)")
.call(yAxis)
.selectAll("path,line")
.attr("fill","none").attr("stroke","black")
.attr("shape-redering","crispEdges");
var xAxis = d3.svg.axis()
.scale(ScatterSample.xScale)
.ticks(5)
.orient("bottom");
svg.append("g")
.attr("transform", "translate(0,250)")
.call(xAxis)
.selectAll("path,line")
.attr("fill","none").attr("stroke","black")
.attr("shape-redering","crispEdges");
}
2013年9月15日日曜日
[Qt] 事始め
C++ で記述されたクロスプラットフォームフレームワークQtを試してみた。
URLを入力してアクセスするだけの超簡易Webブラウザを作ってみた。作ってみたと言っても書いたコードは、数行。FreeBSD 、Windows 7, Windows XP で動かしてみた。



まずは、FreeBSD(xfce)にて
Qt 関連のライブラリが含まれる「Qt」本体(Ver.4.8.2)とQt のIDEである「Qt Creator」(Ver.2.5.0)をコンパイル&インストールする。
cd /usr/ports/devel/qt4
make config-recursive
make
make install
cd /usr/ports/devel/qtcreator
make config-recursive
make
make install
以下がQt Creatorを起動したことろ

まず、コンパイラ関連の設定をする。メインウィンドウの[Tools-Options]でオプションダイアグを開き、ダイアログ左の一覧から「Build & Run」を選択して、「Qt versions」タブを選択。ダイアログ右にある「Add」ボタンをクリックして、先ほどインストールしたQt4本体に含まれる、「qmake-qt4」のPATHを指定します。デフォルトなら、「/usr/local/bin/qmake-qt4」です。
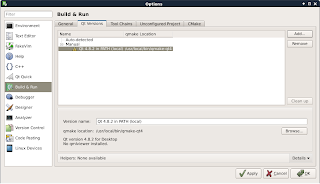
次にどダイアログの「Tool Chains」タブでgcc と gdb のPATHを指定する。ウィンドウ右の「Add」ボタンから「Gcc」を選択。「Compiler path」にgcc(Ver.4.2.1)へのpathを「Debugger」にgdbへのpathを指定する。

これで下準備は、完了。
新しいプロジェクトを作ってコンポーネントをペタペタ貼っていく。

WebブラウザのコンポーネントQWebViewを使った。
コードを数行書く。
-mainwindow.h-
#ifndef MAINWINDOW_H
#define MAINWINDOW_H
#include <QMainWindow>
#include <QDebug>
namespace Ui {
class MainWindow;
}
class MainWindow : public QMainWindow
{
Q_OBJECT
public:
explicit MainWindow(QWidget *parent = 0);
~MainWindow();
private:
Ui::MainWindow *ui;
public slots:
void updateWebPage();
};
#endif // MAINWINDOW_H
Qtの場合イベントを「Signal」といいイベントハンドラを「Slot」という。メインウィンドウのコンストラクタにて、connect関数にて、clicked()というSignalのスロットとしてupdateWebPage()というインプットボックスに入力されたURLをロードする関数を登録する。詳しくは、こちらを参照されたし。
そして、IDE左下の「Run」または、Ctrl+Rで実行できる。



URLを入力してアクセスするだけの超簡易Webブラウザを作ってみた。作ってみたと言っても書いたコードは、数行。FreeBSD 、Windows 7, Windows XP で動かしてみた。



まずは、FreeBSD(xfce)にて
Qt 関連のライブラリが含まれる「Qt」本体(Ver.4.8.2)とQt のIDEである「Qt Creator」(Ver.2.5.0)をコンパイル&インストールする。
cd /usr/ports/devel/qt4
make config-recursive
make
make install
cd /usr/ports/devel/qtcreator
make config-recursive
make
make install
以下がQt Creatorを起動したことろ

まず、コンパイラ関連の設定をする。メインウィンドウの[Tools-Options]でオプションダイアグを開き、ダイアログ左の一覧から「Build & Run」を選択して、「Qt versions」タブを選択。ダイアログ右にある「Add」ボタンをクリックして、先ほどインストールしたQt4本体に含まれる、「qmake-qt4」のPATHを指定します。デフォルトなら、「/usr/local/bin/qmake-qt4」です。

次にどダイアログの「Tool Chains」タブでgcc と gdb のPATHを指定する。ウィンドウ右の「Add」ボタンから「Gcc」を選択。「Compiler path」にgcc(Ver.4.2.1)へのpathを「Debugger」にgdbへのpathを指定する。

これで下準備は、完了。
新しいプロジェクトを作ってコンポーネントをペタペタ貼っていく。

WebブラウザのコンポーネントQWebViewを使った。
コードを数行書く。
-mainwindow.h-
#ifndef MAINWINDOW_H
#define MAINWINDOW_H
#include <QMainWindow>
#include <QDebug>
namespace Ui {
class MainWindow;
}
class MainWindow : public QMainWindow
{
Q_OBJECT
public:
explicit MainWindow(QWidget *parent = 0);
~MainWindow();
private:
Ui::MainWindow *ui;
public slots:
void updateWebPage();
};
#endif // MAINWINDOW_H
-mainwindow.cpp-
#include "mainwindow.h"
#include "ui_mainwindow.h"
#include "mywebview.h"
MainWindow::MainWindow(QWidget *parent) :
QMainWindow(parent),
ui(new Ui::MainWindow)
{
ui->setupUi(this);
connect(ui->goButton, SIGNAL(clicked()), this, SLOT(updateWebPage()));
}
MainWindow::~MainWindow()
{
delete ui;
}
void MainWindow::updateWebPage()
{
ui->webView->setUrl(QUrl(ui->lineEdit->text()));
}
そして、IDE左下の「Run」または、Ctrl+Rで実行できる。

次は、Windows 7で実行してみる。環境がウィンドウズに変わるので再コンパイルが必要です。
C++のコンパイラには、Visual Studio C++付属のclを用います。よってVisua C++ 2010 Expressをインストールしておきます。
さらにQt本体(こちらはバイナリ) (Ver.4.8.2) と Qt Creator (Ver.2.5.2)をDLして、インストールする。
FreeBSDの場合と同様Qt Creatorを起動して、qmakeのpathを指定します。デフォなら「C:\Qt\4.8.2\bin」です。
つぎに、C++コンパイラですが「ツールチェイン」タブにて自動検出されているはずですので手動指定する必要はありません。
FreeBSDで作成した、プロジェクトファイルとコードをWindowsマシンに持ってきて「*.pro」のプロジェクトファイルを開きます。そして、ビルドします。
コンパイルが通ったら早速exeを直接実行したいところですが、Qt関連のライブラリのPATHが通っていないので環境変数PATHにqmakeと同じPATH(C:\Qt\4.8.2\bin\)を追加します。
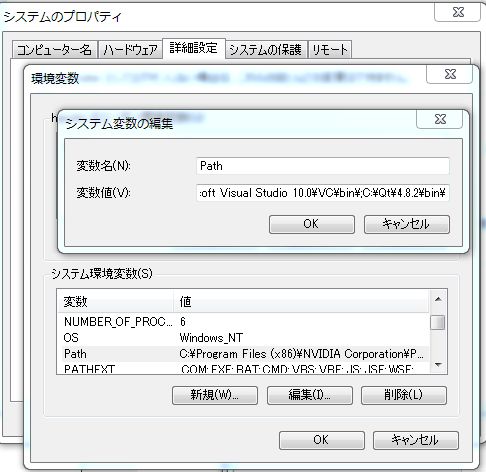
追加が終わったら直接exeを実行することができます。
次は、先ほどWIndows 7でビルドしたexeをWindows XPで実行します。Qt4のライブラリは、必要なのでQt本体をDLしてインストール、qmakeへのパスを環境変数PATHに追加しておきます。
これで実行可能になりました。

2013年9月5日木曜日
[Python] ファイルからの読み込み
超今更なエントリですが、自分自身の知識の定着を図るために書きます。
と言ってもコードは、数行
fp = open('./data/router.log', 'r')
for line in fp:
print type(line)
print line[:-1].split(' ')
fp.close()
-出力-
<type 'str'>
['2013/04/09', '00:55:45:', 'PP[01]', 'IP', 'Commencing', '(DNS', 'Query', '[www.asial.co.jp]', 'from', '192.168.100.2)\r']
<type 'str'>
['2013/04/09', '00:55:46:', 'PP[01]', 'IP', 'Commencing', '(DNS', 'Query', '[api.twitter.com]', 'from', '192.168.100.2)\r']
<type 'str'>
line は、str型なのでsplitメソッドでリストに分解してます。
一行ずつの読み込みは、
fp.readline()
とする方法もあるが、最初の例のほうが高速らしい、
と言ってもコードは、数行
fp = open('./data/router.log', 'r')
for line in fp:
print type(line)
print line[:-1].split(' ')
fp.close()
-出力-
<type 'str'>
['2013/04/09', '00:55:45:', 'PP[01]', 'IP', 'Commencing', '(DNS', 'Query', '[www.asial.co.jp]', 'from', '192.168.100.2)\r']
<type 'str'>
['2013/04/09', '00:55:46:', 'PP[01]', 'IP', 'Commencing', '(DNS', 'Query', '[api.twitter.com]', 'from', '192.168.100.2)\r']
<type 'str'>
line は、str型なのでsplitメソッドでリストに分解してます。
一行ずつの読み込みは、
fp.readline()
とする方法もあるが、最初の例のほうが高速らしい、
2013年8月14日水曜日
[Python] モジュールのサーチパス表示
Python モジュールのサーチパスの表示方法 ( 以下は、Mac OS X での実行結果
>>> import sys
>>> print sys.path
['', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python27.zip', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-darwin', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac/lib-scriptpackages', '/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-tk', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-old', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-dynload', '/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/PyObjC', '/Library/Python/2.7/site-packages']
>>> import sys
>>> print sys.path
['', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python27.zip', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-darwin', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/plat-mac/lib-scriptpackages', '/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-tk', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-old', '/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/lib-dynload', '/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/PyObjC', '/Library/Python/2.7/site-packages']
2013年8月6日火曜日
[python] COMコンポーネントを利用してみる
今回は、WindowsにてpythonでCOMコンポーネントを利用してみます。
pythonは既にインストール済みとして、
まず、必要なライブラリをインストールします。
http://sourceforge.net/projects/pywin32/
からインストールされているpythonのバージョンのインストーラーをダウンロードして、インストール。
これで、[python-install-dir]\Lib\site-packages にライブラリがインストールされます。
次に自分の環境にどのようなCOMコンポーネントがインストールされているか確認する。
Windows SDKをインストールして。以下を管理者権限で実行。
regsvr32 "c:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\IViewers.Dll"
そして、Oleview.exeを管理者権限で実行。ちなみに自分の環境では、C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin に当該プログラムがインストールされていた。
ツリーの「Type Libraries」で各COMコンポーネントのインタフェースを確認することができる。


pythonは既にインストール済みとして、
まず、必要なライブラリをインストールします。
http://sourceforge.net/projects/pywin32/
からインストールされているpythonのバージョンのインストーラーをダウンロードして、インストール。
これで、[python-install-dir]\Lib\site-packages にライブラリがインストールされます。
次に自分の環境にどのようなCOMコンポーネントがインストールされているか確認する。
Windows SDKをインストールして。以下を管理者権限で実行。
regsvr32 "c:\Program Files\Microsoft SDKs\Windows\v7.1\Bin\IViewers.Dll"
そして、Oleview.exeを管理者権限で実行。ちなみに自分の環境では、C:\Program Files\Microsoft SDKs\Windows\v7.1\Bin に当該プログラムがインストールされていた。
ツリーの「Type Libraries」で各COMコンポーネントのインタフェースを確認することができる。

次に、各タイプライブラリのpython用ソースを生成する。win32com clientのインストールディレクトリに移動して、
cd C:\usr\local\python\2_7_5\Lib\site-packages\win32com\client
以下を実行
python makepy.py
すると利用可能なタイプライブラリの一覧が表示されるので。ソースを生成したいライブラリを選択して「OK」を押下。

ここでは、iTunesを選択してみた。生成したタイプライブラリの情報は、
python make.py -i "iTunes 1.13 Type Library"
で確認することができる。
さてようやくサンプルコードですが。。。
>>> import win32com.client
>>> foo = win32com.client.Dispatch("iTunes.Application")
>>> foo.Quit()
ウィンドウを最小化したり、音量を変更したりできるみたいですが今日はここまで
-Reference-
Quick Start to Client side COM and Python
2013年7月30日火曜日
[Network] IPアドレスの衝突
最近普段自分が利用するIPネットワークが不安定にたまにホストの名前解決に失敗する
ネットワークの構成変更をしたばかりでもあり、一番可能性が疑われるIPアドレスの衝突の調査をしてみる。
BSD系OS/Windows
[1] arpテーブルを全て削除
arp -d # BSD系OSの場合 root権限で
[2] テーブルエントリーの追加のために衝突が疑われるアドレスに対してping
ping dst-address
[3] arpテーブルの表示
arp -a
上記手順を数回繰り返して、[3]で表示されるMACアドレスが複数あれば、IPアドレスが衝突していることになる。
ネットワークの構成変更をしたばかりでもあり、一番可能性が疑われるIPアドレスの衝突の調査をしてみる。
BSD系OS/Windows
[1] arpテーブルを全て削除
arp -d # BSD系OSの場合 root権限で
[2] テーブルエントリーの追加のために衝突が疑われるアドレスに対してping
ping dst-address
[3] arpテーブルの表示
arp -a
上記手順を数回繰り返して、[3]で表示されるMACアドレスが複数あれば、IPアドレスが衝突していることになる。
2013年7月23日火曜日
[FreeBSD] GUI環境構築
DM に xfce4 を採用してGUI環境を構築したが、シャットダウン、リブートを一般ユーザーが出来ない
これを解決するためには、/usr/local/etc/polkit-1/localauthority/50-local.d/org.freedesktop.consolekit.pkla を作成して以下を記述する
そして、シャットダウン、リブートを許可したいユーザーをpowerグループに所属させる
これを解決するためには、/usr/local/etc/polkit-1/localauthority/50-local.d/org.freedesktop.consolekit.pkla を作成して以下を記述する
[Local restart]
Idendity=unix-group:power
Action=org.freedesktop.consolekit.system.restart
ResultAny=yes
ResultInactive=yes
ResultActive=yes
[Local shutdown]
Idendity=unix-group:power
Action=org.freedesktop.consolekit.system.stop
ResultAny=yes
ResultInactive=yes
ResultActive=yes
[Local restart - multiple]
Idendity=unix-group:power
Action=org.freedesktop.consolekit.system.restart-multiple-users
ResultAny=yes
ResultInactive=yes
ResultActive=yes
[Local shutdown - multiple]
Idendity=unix-group:power
Action=org.freedesktop.consolekit.system.stop-multiple-users
ResultAny=yes
ResultInactive=yes
ResultActive=yesそして、シャットダウン、リブートを許可したいユーザーをpowerグループに所属させる
2013年7月8日月曜日
[FreeBSD] ports チェックサム unmatched
portsにてgmakeをコンパイル、インストールしようとしたら、チェックサムが合わないと言われた。
make distclean
でダウンロードしてきたファイルを削除して
make checksum
でハッシュ値を計算しなおしたらいけた。
make distclean
でダウンロードしてきたファイルを削除して
make checksum
でハッシュ値を計算しなおしたらいけた。
[libxml2] XPath によるxmlのパース
APIの多さと初心者向けの情報の少なさで苦戦してますが、ようやく超最低限なパースができたのでメモ
パースするXMLファイル
<?xml version="1.0" encoding="us-ascii" ?>
<orchestra>
<players num="3">
<player>aoki</player>
<player>nakashima</player>
<player>suzuki</player>
</players>
</orchestra>
パースするXMLファイル
<?xml version="1.0" encoding="us-ascii" ?>
<orchestra>
<players num="3">
<player>aoki</player>
<player>nakashima</player>
<player>suzuki</player>
</players>
</orchestra>
コード
#include <stdio.h>
#include <libxml/xmlreader.h>
#include <libxml/xpath.h>
int main(int argc, char **argv){
char *xml;
char *xmlPath;
int i;
xmlXPathContextPtr cntxt;
xmlXPathObjectPtr xmlObj;
xmlDocPtr doc;
xmlNodeSetPtr nodes;
xmlNodePtr node;
struct _xmlAttr *curAttr;
xml = argv[1];
xmlPath = argv[2];
doc = xmlParseFile(xml);
if(!doc) return -1;
cntxt = xmlXPathNewContext(doc);
if(!cntxt) return -1;
xmlObj = xmlXPathEvalExpression((xmlChar *) xmlPath, cntxt);
if(!xmlObj) return -1;
nodes = xmlObj->nodesetval;
// iterate node
for(i=0;i<nodes->nodeNr; i++){
node = xmlXPathNodeSetItem(nodes, i);
// node name
printf("=%s=\n", node->name);
// properties
curAttr = node->properties;
while( curAttr != NULL ){
printf("%s: %s\n", curAttr->name, curAttr->children->content);
curAttr = curAttr->next;
}
if(node->children->content != NULL ){
printf("content= %s\n", node->children->content);
}
}
xmlXPathFreeContext(cntxt);
xmlFreeDoc(doc);
xmlCleanupParser();
return 0;
}
実行
./a.out sample/01.xml "//*"
出力
=orchestra=
content=
=players=
num: 3
content=
=player=
content= aoki
=player=
content= nakashima
=player=
content= suzuki
上記サンプルには、値を含んでいないcontentのケアを含んでいない。
参考サイト: http://d.hatena.ne.jp/hakutoitoi/20090319/1237397160 取っ掛かりのコード
2013年6月28日金曜日
[FreeBSD] Sieve を書いてみた
Sieve は、メールフィルタリングのための言語です。
メールサーバー上にフィルタリングルールを定義したファイルを予め置いておき、サーバー上でメールをフィルタリングすることでクライアントの環境に依存しない点が売りです。
今回は、Sieve の Dovecot 向け実装であるPIGENHOLEをインストールしてみました。
[A] インストール
インストール自体は、メールサーバーにて
cd /usr/ports/mail/dovecot2-pgenhole/
make config-recursive
make
make install clean
で終了。
PIGENHOLE のSieve は、Dovecotのプラグインとして提供されているのでこのプラグインを有効にします。この設定は、受信したメールのローカルユーザーへの配信をLDA/LMTPのどちらで行なっているかに依存するので予め確認しておく必要があります。デフォルトでは、LDAを用いているようです。
以下LDAの場合の例 /usr/local/etc/dovecot/conf.d/90-plugin.conf に以下を追加
protocol lda{
mail_plugins = sieve
}
[B} フィルタリングルール作成
フィルタリングルールは、ルールを適用したいユーザーのホームディレクトリに「.dovecot.sieve」を作成してこのファイルの中に記述していきます。
以下はそのサンプル。
require ["fileinto"];
if address :is "from" "foo@example.jp" {
fileinto "INBOX.spam";
}
foo@example.jp からのメールをspamフォルダーに振り分けます。そしてこの.dovecot.sieveを以下コマンドでコンパイルして「~/.dovecot.svbin」として出力します。
sievec ~/.dovecot.sieve ~/.dovecot.svbin
これで次回メール受信時から作成したルールが適用されます。ルールが適用されないようであれば~/.dovecot.sieve.log にログが出力されるので参考にします。
今回は、ここまで
今後は、スクリプトファイルのUNICODE対応やThunderbirdのsieveのスクリプトを編集できるAdd On等を試してみたい。。。
メールサーバー上にフィルタリングルールを定義したファイルを予め置いておき、サーバー上でメールをフィルタリングすることでクライアントの環境に依存しない点が売りです。
今回は、Sieve の Dovecot 向け実装であるPIGENHOLEをインストールしてみました。
[A] インストール
インストール自体は、メールサーバーにて
cd /usr/ports/mail/dovecot2-pgenhole/
make config-recursive
make
make install clean
で終了。
PIGENHOLE のSieve は、Dovecotのプラグインとして提供されているのでこのプラグインを有効にします。この設定は、受信したメールのローカルユーザーへの配信をLDA/LMTPのどちらで行なっているかに依存するので予め確認しておく必要があります。デフォルトでは、LDAを用いているようです。
以下LDAの場合の例 /usr/local/etc/dovecot/conf.d/90-plugin.conf に以下を追加
protocol lda{
mail_plugins = sieve
}
[B} フィルタリングルール作成
フィルタリングルールは、ルールを適用したいユーザーのホームディレクトリに「.dovecot.sieve」を作成してこのファイルの中に記述していきます。
以下はそのサンプル。
require ["fileinto"];
if address :is "from" "foo@example.jp" {
fileinto "INBOX.spam";
}
foo@example.jp からのメールをspamフォルダーに振り分けます。そしてこの.dovecot.sieveを以下コマンドでコンパイルして「~/.dovecot.svbin」として出力します。
sievec ~/.dovecot.sieve ~/.dovecot.svbin
これで次回メール受信時から作成したルールが適用されます。ルールが適用されないようであれば~/.dovecot.sieve.log にログが出力されるので参考にします。
今回は、ここまで
今後は、スクリプトファイルのUNICODE対応やThunderbirdのsieveのスクリプトを編集できるAdd On等を試してみたい。。。
2013年6月27日木曜日
[FreeBSD] dovecot2 のインストール
要点のみをかいつまんで。。。
1) コンパイル と インストール
2) 設定ファイル例をコピー
/usr/local/share/doc/dovecot 以下の dovecot.conf と conf.d ディレクトリを /usr/lolcal/etc/dovecot にコピー
3) 認証プロトコルの設定
今回は、テスト用途なんで plain 認証でいきます。 先ほどコピーしたconf.d ディレクトリ中の
10-ssl.conf 中の
#ssl =yes
を
ssl = no
に変更し、同ディレクトリ中の 10-auth.conf の
#disable_plaintext_auth = yes
を
disable_plaintext_auth = no
とし、明示的にsslを使わない様に変更。これに気づかずかなり時間を食った
4) デーモンプロセス 始動
/usr/local/etc/rc.d/postfix
起動時に自動でデーモンを起動した場合は、
/etc/rc.conf に以下を追加
dovecot_enable="YES"
1) コンパイル と インストール
2) 設定ファイル例をコピー
/usr/local/share/doc/dovecot 以下の dovecot.conf と conf.d ディレクトリを /usr/lolcal/etc/dovecot にコピー
3) 認証プロトコルの設定
今回は、テスト用途なんで plain 認証でいきます。 先ほどコピーしたconf.d ディレクトリ中の
10-ssl.conf 中の
#ssl =yes
を
ssl = no
に変更し、同ディレクトリ中の 10-auth.conf の
#disable_plaintext_auth = yes
を
disable_plaintext_auth = no
とし、明示的にsslを使わない様に変更。これに気づかずかなり時間を食った
4) デーモンプロセス 始動
/usr/local/etc/rc.d/postfix
起動時に自動でデーモンを起動した場合は、
/etc/rc.conf に以下を追加
dovecot_enable="YES"
2013年6月26日水曜日
2013年6月10日月曜日
[FreeBSD] Windows の共有ディレクトリをマウント
CentOS に続き FreeBSDでも
mount_smb -I host-addr //host-name/ /mnt/path-to-mount-point
ex) mount_smb -I 192.168.100.2 //win-pc/ /mnt/windir
2013年5月15日水曜日
[Code reading] time command
[Motivation]
FORTRANで記述されコンパイラで自動並列化した数値解析のプログラムの実行時間を下記環境でtimeコマンドを使って測定したら下記の様な結果になった。
-実行環境-
OS: Cent OS
CPU: Intel Xeon Processor L5640 x 2
-並列数-
OMP_NUM_THREAD=12
-time コマンド結果-
real 84m23.521s
user 1010m2.767s
sys 0m7.199s
[reasoning]
user時間は、各コアのuser時間の合計となるためスレッド並列化して実行したコマンドでは、real時間よりも長くなることがある?
適当なミラーサイトからソースを取ってくる。
後、linuxカーネル(2.6.34)のソースも取ってくる。
まずは、タイムコマンドのmain関数
-time.c: main
632 main (argc, argv)
633 int argc;
634 char **argv;
635 {
636 const char **command_line;
637 RESUSE res;
…
640 run_command (command_line, &res);
641 summarize (outfp, output_format, command_line, &res);
run_commandという関数を見てみる
-time.c: run_command
597 static void
598 run_command (cmd, resp)
599 char *const *cmd;
600 RESUSE *resp;
601 {
…
605 resuse_start (resp);
…
614 execvp (cmd[0], cmd);
…
623 if (resuse_end (pid, resp) == 0)
timeコマンドで指定したコマンドをexecvp関数で実行している.
execvp関数の前後で呼んでいるresuseで始まる関数を次に見てみる
-resuse.c: resuse_start
46 void
47 resuse_start (resp) //resuseは、resource use startの略と思われる。
48 RESUSE *resp;
49 {
50 #if HAVE_WAIT3
51 gettimeofday (&resp->start, (struct timezone *) 0);
52 #else
53 long value;
54 struct tms tms;
55
56 value = times (&tms); // man によると返り値は過去のある時点からのtick
57 resp->start.tv_sec = value / HZ; // HZ は、CPUクロックか? 確証は得られてない
58 resp->start.tv_usec = value % HZ * (1000000 / HZ);
59 #endif
60 }
現在のクロックカウント(と言っていいのか?)をHZで割って時刻をresp->start.tvに保持する
-resuse.c: resuse_end
117 resp->elapsed.tv_sec -= resp->start.tv_sec; // real time (sec)?
124 resp->elapsed.tv_usec -= resp->start.tv_usec; // real time (micro sec)?
コマンド実行後に省略したが同様にCPU時刻を取得して実行前の時刻を引いている。=> 正味実行にかかった時間(real time)を算出。
struct tmsとは何か?
struct tms -> linux/times.h
6 struct tms {
7 __kernel_clock_t tms_utime; // user time
8 __kernel_clock_t tms_stime; // system time
9 __kernel_clock_t tms_cutime; // child process user time
10 __kernel_clock_t tms_cstime; // child process system time
11 };
__kernel_clock_t -> linux/types.h
79 typedef __kernel_clock_t clock_t;
-time.c : summarize
320 static void
321 summarize (fp, fmt, command, resp)
322 FILE *fp;
323 const char *fmt;
324 const char **command;
325 RESUSE *resp;
326 {
-kernel/sys.c 912 void do_sys_times(struct tms *tms)
921 tms->tms_utime = cputime_to_clock_t(tgutime);
922 tms->tms_stime = cputime_to_clock_t(tgstime);
923 tms->tms_cutime = cputime_to_clock_t(cutime);
924 tms->tms_cstime = cputime_to_clock_t(cstime);
thread_group_timesとは
kernel/sched.c
3398 void thread_group_times(struct task_struct *p, cputime_t *ut, cputime_t *st)
3399 {
3400 struct task_cputime cputime;
3401
3402 thread_group_cputime(p, &cputime);
3403
3404 *ut = cputime.utime;
3405 *st = cputime.stime;
3406 }
kernel/posix_cpu_timers.c
234 void thread_group_cputime(struct task_struct *tsk, struct task_cputime *times)
235 {
236 struct sighand_struct *sighand;
237 struct signal_struct *sig;
238 struct task_struct *t;
239
240 *times = INIT_CPUTIME;
241
242 rcu_read_lock();
243 sighand = rcu_dereference(tsk->sighand);
244 if (!sighand)
245 goto out;
246
247 sig = tsk->signal;
248
249 t = tsk;
250 do {
251 times->utime = cputime_add(times->utime, t->utime);
252 times->stime = cputime_add(times->stime, t->stime);
253 times->sum_exec_runtime += t->se.sum_exec_runtime;
254
255 t = next_thread(t);
256 } while (t != tsk);
257
258 times->utime = cputime_add(times->utime, sig->utime);
259 times->stime = cputime_add(times->stime, sig->stime);
260 times->sum_exec_runtime += sig->sum_sched_runtime;
261 out:
262 rcu_read_unlock();
263 }
include/asm-generic/cputime.h
12 #define cputime_add(__a, __b) ((__a) + (__b))
next_thread(t);とは
include/linux/sched.h
2177 static inline struct task_struct *next_thread(const struct task_struct *p)
2178 {
2179 return list_entry_rcu(p->thread_group.next,
2180 struct task_struct, thread_group);
2181 }
thread_group.nextとは、
include/linux/sched.hのtask_structのメンバー
1285 struct list_head thread_group;
list_headとは、
include/linux/list.h
41 struct list_head {
42 struct list_head *next, *prev;
43 };
list_entry_rcuとは?
include/linux/rculist.h
210 #define list_entry_rcu(ptr, type, member) \
211 container_of(rcu_dereference_raw(ptr), type, member)
spin_lock_irq のirqとは?
include/linux/spinlock.h
307 static inline void spin_lock_irq(spinlock_t *lock)
308 {
309 raw_spin_lock_irq(&lock->rlock);
310 }
include/linux/spinlock.h
220 #define raw_spin_lock_irq(lock) _raw_spin_lock_irq(lock)
include/linux/spinlock-api_up.h
59 #define _raw_spin_lock_irq(lock) __LOCK_IRQ(lock)
spin_local_irqに渡しているcurrent_sighand_siglockとは?
[conclusion]
utimeとstimeは、とりあえず全てのスレッド分足してそうだというとこまでは行ったがかなり消化不足気味
[気になるキーワード]
Hyper Threading
SMT (Simultaneous Multi Threading) 同時マルチスレッディング
SMP (Symmetric Multi Processing) 対象型マルチプロセシング
FORTRANで記述されコンパイラで自動並列化した数値解析のプログラムの実行時間を下記環境でtimeコマンドを使って測定したら下記の様な結果になった。
-実行環境-
OS: Cent OS
CPU: Intel Xeon Processor L5640 x 2
-並列数-
OMP_NUM_THREAD=12
-time コマンド結果-
real 84m23.521s
user 1010m2.767s
sys 0m7.199s
[reasoning]
user時間は、各コアのuser時間の合計となるためスレッド並列化して実行したコマンドでは、real時間よりも長くなることがある?
[research]
適当なミラーサイトからソースを取ってくる。
後、linuxカーネル(2.6.34)のソースも取ってくる。
まずは、タイムコマンドのmain関数
-time.c: main
632 main (argc, argv)
633 int argc;
634 char **argv;
635 {
636 const char **command_line;
637 RESUSE res;
…
640 run_command (command_line, &res);
641 summarize (outfp, output_format, command_line, &res);
run_commandという関数を見てみる
-time.c: run_command
597 static void
598 run_command (cmd, resp)
599 char *const *cmd;
600 RESUSE *resp;
601 {
…
605 resuse_start (resp);
…
614 execvp (cmd[0], cmd);
…
623 if (resuse_end (pid, resp) == 0)
timeコマンドで指定したコマンドをexecvp関数で実行している.
execvp関数の前後で呼んでいるresuseで始まる関数を次に見てみる
-resuse.c: resuse_start
46 void
47 resuse_start (resp) //resuseは、resource use startの略と思われる。
48 RESUSE *resp;
49 {
50 #if HAVE_WAIT3
51 gettimeofday (&resp->start, (struct timezone *) 0);
52 #else
53 long value;
54 struct tms tms;
55
56 value = times (&tms); // man によると返り値は過去のある時点からのtick
57 resp->start.tv_sec = value / HZ; // HZ は、CPUクロックか? 確証は得られてない
58 resp->start.tv_usec = value % HZ * (1000000 / HZ);
59 #endif
60 }
現在のクロックカウント(と言っていいのか?)をHZで割って時刻をresp->start.tvに保持する
-resuse.c: resuse_end
117 resp->elapsed.tv_sec -= resp->start.tv_sec; // real time (sec)?
124 resp->elapsed.tv_usec -= resp->start.tv_usec; // real time (micro sec)?
コマンド実行後に省略したが同様にCPU時刻を取得して実行前の時刻を引いている。=> 正味実行にかかった時間(real time)を算出。
struct tmsとは何か?
struct tms -> linux/times.h
6 struct tms {
7 __kernel_clock_t tms_utime; // user time
8 __kernel_clock_t tms_stime; // system time
9 __kernel_clock_t tms_cutime; // child process user time
10 __kernel_clock_t tms_cstime; // child process system time
11 };
__kernel_clock_t -> linux/types.h
79 typedef __kernel_clock_t clock_t;
-time.c : summarize
320 static void
321 summarize (fp, fmt, command, resp)
322 FILE *fp;
323 const char *fmt;
324 const char **command;
325 RESUSE *resp;
326 {
-kernel/sys.c 912 void do_sys_times(struct tms *tms)
921 tms->tms_utime = cputime_to_clock_t(tgutime);
922 tms->tms_stime = cputime_to_clock_t(tgstime);
923 tms->tms_cutime = cputime_to_clock_t(cutime);
924 tms->tms_cstime = cputime_to_clock_t(cstime);
thread_group_timesとは
kernel/sched.c
3398 void thread_group_times(struct task_struct *p, cputime_t *ut, cputime_t *st)
3399 {
3400 struct task_cputime cputime;
3401
3402 thread_group_cputime(p, &cputime);
3403
3404 *ut = cputime.utime;
3405 *st = cputime.stime;
3406 }
kernel/posix_cpu_timers.c
234 void thread_group_cputime(struct task_struct *tsk, struct task_cputime *times)
235 {
236 struct sighand_struct *sighand;
237 struct signal_struct *sig;
238 struct task_struct *t;
239
240 *times = INIT_CPUTIME;
241
242 rcu_read_lock();
243 sighand = rcu_dereference(tsk->sighand);
244 if (!sighand)
245 goto out;
246
247 sig = tsk->signal;
248
249 t = tsk;
250 do {
251 times->utime = cputime_add(times->utime, t->utime);
252 times->stime = cputime_add(times->stime, t->stime);
253 times->sum_exec_runtime += t->se.sum_exec_runtime;
254
255 t = next_thread(t);
256 } while (t != tsk);
257
258 times->utime = cputime_add(times->utime, sig->utime);
259 times->stime = cputime_add(times->stime, sig->stime);
260 times->sum_exec_runtime += sig->sum_sched_runtime;
261 out:
262 rcu_read_unlock();
263 }
include/asm-generic/cputime.h
12 #define cputime_add(__a, __b) ((__a) + (__b))
next_thread(t);とは
include/linux/sched.h
2177 static inline struct task_struct *next_thread(const struct task_struct *p)
2178 {
2179 return list_entry_rcu(p->thread_group.next,
2180 struct task_struct, thread_group);
2181 }
thread_group.nextとは、
include/linux/sched.hのtask_structのメンバー
1285 struct list_head thread_group;
list_headとは、
include/linux/list.h
41 struct list_head {
42 struct list_head *next, *prev;
43 };
list_entry_rcuとは?
include/linux/rculist.h
210 #define list_entry_rcu(ptr, type, member) \
211 container_of(rcu_dereference_raw(ptr), type, member)
spin_lock_irq のirqとは?
include/linux/spinlock.h
307 static inline void spin_lock_irq(spinlock_t *lock)
308 {
309 raw_spin_lock_irq(&lock->rlock);
310 }
include/linux/spinlock.h
220 #define raw_spin_lock_irq(lock) _raw_spin_lock_irq(lock)
include/linux/spinlock-api_up.h
59 #define _raw_spin_lock_irq(lock) __LOCK_IRQ(lock)
spin_local_irqに渡しているcurrent_sighand_siglockとは?
[conclusion]
utimeとstimeは、とりあえず全てのスレッド分足してそうだというとこまでは行ったがかなり消化不足気味
[気になるキーワード]
Hyper Threading
SMT (Simultaneous Multi Threading) 同時マルチスレッディング
SMP (Symmetric Multi Processing) 対象型マルチプロセシング
[Visual Studio C++] PEバイナリのエクスポートされたシンボル
PEバイナリのエクスポートされたシンボル名を確認する
漢は黙ってバイナリエディタといきたいとこだけど
今回は、MSさんのツール(dumpbin)を使います。
このdumpbinは、Visual Studioを使うと [Install Direcotry]\VC\bin にインストールされます。
ここは、PATHが通ってないし、dumpbinが使うライブラリがあるPATHがサーチパスに含まれてないため、dumpbin.exeと同一ディレクトリにあるバッチファイル vcvars32.bat を実行する必要があります。
そして、
dumpbin /EXPORT input.dll
とすることでシンボル名を確認することができる。
漢は黙ってバイナリエディタといきたいとこだけど
今回は、MSさんのツール(dumpbin)を使います。
このdumpbinは、Visual Studioを使うと [Install Direcotry]\VC\bin にインストールされます。
ここは、PATHが通ってないし、dumpbinが使うライブラリがあるPATHがサーチパスに含まれてないため、dumpbin.exeと同一ディレクトリにあるバッチファイル vcvars32.bat を実行する必要があります。
そして、
dumpbin /EXPORT input.dll
とすることでシンボル名を確認することができる。
[c言語] Windows と Linux の共有ライブラリ
分けあってWindows向けの共有ライブラリ(dll) と Linux向けの共有ライブラリ(so) を
一つのC言語のソースで用意する必要が生じだ。
後にも先にもこれ一回限りな気がするけど一応メモ
検証環境は、
Windows 7 64bit版 C Compiler: gcc ライブラリを使う言語とコンパイラ Delphi XE2
Linux (RHEL) C Compiler: gcc ライブラリを使う言語とコンパイラ Fortran 90 pgfortran
まずは、ヘッダファイルとソース
add.h
#ifndef ADD_H
#define ADD_H
int add_(int *a, int *b)
int devide_(float *a, float *b, float *c)
#endif
一つのC言語のソースで用意する必要が生じだ。
後にも先にもこれ一回限りな気がするけど一応メモ
検証環境は、
Windows 7 64bit版 C Compiler: gcc ライブラリを使う言語とコンパイラ Delphi XE2
Linux (RHEL) C Compiler: gcc ライブラリを使う言語とコンパイラ Fortran 90 pgfortran
まずは、ヘッダファイルとソース
add.h
#ifndef ADD_H
#define ADD_H
int add_(int *a, int *b)
int devide_(float *a, float *b, float *c)
#endif
add.c
#include<stdio.h>
int add_(int *a, int *b){
int c;
c = *a + *b;
return c;
}
int devide_(float *a, float *b, float *c){
*c = *a / *b;
return 0;
}
ポイントは、引数がすべて参照渡しになっている点です。 Fortranが参照渡しがデフォルトなためです。 また、関数名がアンダースコアで終わっているのは、また後で。。。
お次は、コンパイル
まずは、Windowsで
gcc -shared -m32 -o add.dll add.c
-m32 は、32bi tPEバイナリを出力するためのオプションでdllを使う、アプリケーション(exe)が32bitであるため。
次に、Linuxで
gcc -fPIC -shared -o libadd.so add.c
-fPICは、位置独立コード(Position Independent Code)というメモリのどのアドレにもロード可能にするためのオプションです。
そして、使う側。
まずは、Delphi
unit use;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls;
type
TForm6 = class(TForm)
Button1: TButton;
procedure Button1Click(Sender: TObject);
private
{ Private 宣言 }
public
{ Public 宣言 }
end;
TAdd = function(a : PInteger; b : PInteger) : integer ; stdcall;
TDevide = function(a : PSingle; b : PSingle; c : PSingle) : integer ; stdcall;
var
Form6: TForm6;
implementation
{$R *.dfm}
procedure TForm6.Button1Click(Sender: TObject);
var
ret : integer;
a,b : integer;
c,d,e : single;
Handle : THandle;
Add : TAdd;
Devide : TDevide;
begin
a := 4;
b := 2;
c := 4.0;
d := 2.0;
Handle := LoadLibrary('add.dll');
if Handle <> 0 then
begin
@Add := GetProcAddress(Handle, 'add_');
if @Add <> nil then
begin
ret := add(@a, @b);
ShowMessage(IntToStr(ret));
end;
@Devide := GetProcAddress(Handle, 'devide_');
if @Devide <> nil then
begin
ret := devide(@c, @d, @e);
ShowMessage(FloatToStr(e));
end;
FreeLibrary(Handle);
end;
end;
end.
関数をtypedefして、GetProcAddress にて関数のあるアドレスを取得する。
次は、Linux上のFortran
interface節を記述したインクルードファイルを作成
addf.h
interface
integer function add(a,b)
integer a,b
end function add
integer function devide(a,b,c)
real a,b,c
end function devide
end interface
次にFortranのソース本体
program test
include 'addf.h'
integer c,d
real e,f,g
c=4
d=2
e=4.0
f=2.0
d = add(c,d)
i = devide(e,f,g)
write(*,*) d,g,i
end program test
そしてコンパイル
pgfortran -I./include -L./lib -ladd src/use.f
-l で使用するライブラリを指定します。
また、Fortranの場合、関数名は、アンダースコアがついたシンボルを探すのでCの関数名には、アンダースコアをつける必要があります。
2013年5月2日木曜日
[CentOS] コマンドラインでWindowsなホストの共有ディレクトリをマウント
Windows独自プロトコルであるSMB (Server Message Block)を拡張仕様公開した、CIFS を実装してGPL v3 にて公開しているのがSamba ということらしいのですが
今回は、mountコマンドにてWindowsなホストで共有でしているディレクトリをCentOS release 6.4 にてマウントしてみます。
まず、必要パッケージのインストール
yum -y install samba-client
yum -y install cifs-utils
必要に応じてマウントポイントの作成
mkdir -p /mnt/winshare
そして、マウント
mount -t cifs //192.168.100.2/Users/hoge /mnt/winshare -o username=hoge
実行するとWindows上の共有しているディレクトリへのアクセス権のあるWindowsドメインのユーザーアカウントのパスワードを聞かれるので入力する。
192.168.200.2は、WindowsホストのIPアドレス
今回は、mountコマンドにてWindowsなホストで共有でしているディレクトリをCentOS release 6.4 にてマウントしてみます。
まず、必要パッケージのインストール
yum -y install samba-client
yum -y install cifs-utils
必要に応じてマウントポイントの作成
mkdir -p /mnt/winshare
そして、マウント
mount -t cifs //192.168.100.2/Users/hoge /mnt/winshare -o username=hoge
実行するとWindows上の共有しているディレクトリへのアクセス権のあるWindowsドメインのユーザーアカウントのパスワードを聞かれるので入力する。
192.168.200.2は、WindowsホストのIPアドレス
2013年4月29日月曜日
[CentOS] Building Bewulf type PC cluster
Bewulf型PCクラスタを構築してみる。
目標は、
「MPIライブラリを使ったサンプルプログラムを複数ノードで実行する」
今回構築するクラスタの概要は、
*ヘッドノード、スレーブノード2ノードの計3ノード
*すべてのノードは、CentOS release 6.4 minimal
*ヘッドノードは、/home のみをNFSにて共有する(ディスクレスに挑戦したかったけどまた今度
ネットワークは、下図の様になる。
 192.168.200.0/24がクラスタ専用のネットワークです。
192.168.200.0/24がクラスタ専用のネットワークです。
各ノードのスペックは、
node name CPU RAM HDD
bwhead amd64 (1 core)*1 2 Gbyte 50Gbyte x 2*2
bwslv01 amd64 (1 core) 1 Gbyte 50 GByte
bqslv02 amd64 (1 core) 1Gbyte 50 GByte
*1 型名になっていないのは、今回構築したノードすべてが仮想マシンだからです。
*2 /home 用に1台、/用に1台
-目次-
[0] HeadノードへのOSのインストール























[1] Head ノードの設定
A) ネットワークインターフェースの設定
前述のネットワーク構成図に沿って設定します。
/etc/sysconfig/network-scripts/ifcfg-eth0
ONBOOT=yes
BOOTPROTO=dhcp
/etc/sysconfig/network-scripts/ifcfg-eth1
ONBOOT=yes
BOOTPROTO=static
IPPADDR=192.168.200.1
NETMASK=255.255.255.0
B) /etc/hosts の編集
以下を追加
192.168.200.1 bwhead
192.168.200.2 bwslv01
192.168.200.3 beslv02
上記の編集を反映させるためにネットワークサービスを再始動
/etc/init.d/networking restart
C) DHCPサーバーのインストール
slaveノードへのOSのインストールは、物理マシンでの構築の演習としてPXEによるネットワークブートとします。ネットワークブートでは、ブートローダーの場所等の情報を配布するのにDHCPを用います。そこでDHCPサーバーを構築します。
yum list dhcp
でパッケージを検索
yum install dhcp
そして、設定ファイルを作成
---- /etc/dhcp/dhcpd.conf ------
#
# DHCP Server Configuration file.
# see /usr/share/doc/dhcp*/dhcpd.conf.sample
# see 'man 5 dhcpd.conf'
#
DHCPDARGS=eth1;
# network boot setttings
allow booting;
allow bootp;
option option-128 code 128 = string;
option option-129 code 129 = text;
next-server 192.168.200.1;
filename "pxelinux.0";
subnet 192.168.200.0 netmask 255.255.255.0{
# default gateway
option routers 192.168.200.1;
option subnet-mask 255.255.255.0;
option domain-name-servers 192.168.100.1;
range 192.168.200.100 192.168.200.254;
default-lease-time 21600;
max-lease-time 43200;
host bwslv01{
hardware ethernet 08:00:27:9C:25:55;
option host-name "bwslv01";
fixed-address 192.168.200.2;
}
host bwslv02{
hardware ethernet 08:00:27:29:4E:37;
option host-name "bwslv02";
fixed-address 192.168.200.3;
}
}
------------------------------------
設定ファイルの構文チェック
service dhcpd configtest
service dhcpd start
chkconfig dhcpd on
dhcpの使うポートを開けておく
iptables -I INPUT -i eth1 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
再起動時に設定が無効にならないように
/etc/init.d/iptables save
ファイヤーウォールの再起動
/etc/init.d/iptables restart
D) tftpサーバーのインストール
ネットワークブートにおいてブートローダ等を配布するのに必要
yum install tftp tftp-server
/etc/xinetd.d/tfptd
chkconfig xinetd on
service xnetd start
chkconfig tftp on
E) slave ネットワークブートのための準備
syslinuxをインストールします。
yum install syslinux
PXEブートにブートローダ関係の必要なファイルをtftpの公開ディレクトリにコピーします。
cp /usr/lib/syslinux/pxelinux.0 /var/lib/tftpboot
cp /usr/lib/syslinux/menu.c32 /var/lib/tftpboot
cp /usr/lib/syslinux/memdisk /var/lib/tftpboot
cp /usr/lib/syslinux/mboot.c32 /var/lib/tftpboot
cp /usr/lib/syslinux/chain.c32 /var/lib/tftpboot
OS関係の必要なファイルをtftpサーバーの公開ディレクトリに取ってきます。
yum install wget
mkdir -p /tftpboot/images/centos/x86_64/6.4
cd /var/lib/tftpboot/images/centos/
wget http://linux.mirrors.es.net/centos/6.4/os/x86_64/images/pxeboot/initrd.img
wget http://linux.mirrors.es.net/centos/6.4/os/x86_64/images/pxeboot/vmlinuz
ブートローダメニューの設定ファイルを作成
---/var/lib/tftpboot/pxelinux.cfg/default---
default menu.c32
prompt 0
timeout 300
INTIMEOUT local
MENU TITLE PXE Menu
LABEL local
MENU LABEL Boot from local hard disk drive
LOCALBOOT 0
LABEL CentOS 6.4 x86_64
MENU LABEL CentOS 6.4 x86_64
KERNEL images/centos/6.4/x86_64/vmlinuz
APPEND load initrd=images/centos/6.4/x86_64/initrd.img devfs=nomount
--------------------------------------
tftp(udp 69番ポート)を開ける
iptables -A INPUT -m state --state NEW -i eth0 -p udp --dport 69 -j ACCEPT
再起動時に設定が無効にならないように
/etc/init.d/iptables save
ファイヤーウォールの再起動
/etc/init.d/iptables restart
フォワーディングを有効にする
-- /etc/sysctl.conf--
# Controls IP packet forwarding
net.ipv4.ip_forward = 1 # 0 から 1に変更
----------------------
[2] slavve ノードのOSインストール









これ以降は、Headノードと同じGUIなインストーラーが起動しての同じインストールとなる。
[3] ssh でのhead から slave へのパスワード無しログイン
MPIライブラリのデータの移動、設定ファイルの配布のための仕組みを構築します。
よくr系コマンドが用いられますが、自分の環境では、rootでのパスワード無しログインが
できるようにすることを断念したため、sshを用います。
A) slave ノードへssh-server のインストール
yum install openssh-server
scpを使うため
yum install openssh-client
/etc/ssh/sshd_configの以下のコメントをはずす
#PermitRootLogin yes -> PermitRootLogin yes
chkconfig ssh on
service sshd start
試しにrootで全てのslaveノードにログインしてみる
ssh root@192.168.200.n # n は、整数
ログインしたまま後の作業の準備
cd $HOME
mkdir .ssh
B) head ノードでの作業
公開鍵生成
ssh-keygen -b 1024 -t rsa
鍵のパスフレーズは空にしておく
公開鍵を全てのslaveノードに配布しておく。
scp ~/.ssh/id_rsa.pub root@192.168.200.n:.ssh/authorized_keys
クラスタは、外からの開始される接続を許可しないネットワーク内で運用するのでとりあえずSElinuxは無効化しておく。
setenforce 0
そして、起動後も無効になるように/etc/selinux/configのSELINUXTYPEを下記のようにdisabledに変更しておく。
SELINUXTYPE=diabled
C)シェルスクリプトの作成
各ノードに同様の実行するためのシェルスクリプトを用意( rshでも実現可能だが自分の環境では、rootでの実行がPermission Denied ど言われで実現できなかった
----${HOME}/utils/rssh.sh-----
#!/bin/bash
BEGIN_ADDR=2
END_ADDR=3
ADDR_PREFIX="192.168.200."
for i in `seq $BEGIN_ADDR $END_ADDR`
do
DST_ADDR="$ADDR_PREFIX$i"
echo "Processing for $DST_ADDR"
ssh $DST_ADDR<<EOF
$*
EOF
done
---------------------------
chmod 744 ${HOME}/utils/rssh.sh
各ノードにファイルコピーするためのコマンド
---${HOME}/utils/rsscp.sh---
#!/bin/bash
SRC_FILE=$1
DST_PATH=$2
BEGIN_ADDR=2
END_ADDR=3
ADDR_PREFIX="192.168.200."
for i in `seq $BEGIN_ADDR $END_ADDR`
do
DST_ADDR="$ADDR_PREFIX$i"
echo "Copying $SRC_FILE -> $DST_ADDR:$DST_PATH"
scp $SRC_FILE $DST_ADDR:$DST_PATH
done
--------------------------
D) /etc/hosts の配布
/etc/hosts を作成して
${HOME}/utils/rsscp.sh /etc/hosts /etc/hosts
[4] NIS を用いたアカウント一元管理
A) サーバーの構築
アカウントを一括管理するためにNISサーバーを構築する
まずは、サーバーのインストール
yum install ypserv
ドメインの設定 このドメインは、DNSとは関係がない
ypdomainname clnet
/etc/sysconfig/network に 先ほど設定したNISドメインを追加
NISDOMAIN = clnet
/var/yp/Makefile の編集(下記がオリジナルのファイルとの差分)
-----差分-----------------------
*** Makefile.org 2013-04-27 17:41:09.642037547 +0900
--- Makefile 2013-04-27 17:42:41.594036564 +0900
***************
*** 39,49 ****
# Should we merge the passwd file with the shadow file ?
# MERGE_PASSWD=true|false
! MERGE_PASSWD=true
# Should we merge the group file with the gshadow file ?
# MERGE_GROUP=true|false
! MERGE_GROUP=true
# These are commands which this Makefile needs to properly rebuild the
# NIS databases. Don't change these unless you have a good reason.
--- 39,49 ----
# Should we merge the passwd file with the shadow file ?
# MERGE_PASSWD=true|false
! MERGE_PASSWD=false
# Should we merge the group file with the gshadow file ?
# MERGE_GROUP=true|false
! MERGE_GROUP=false
# These are commands which this Makefile needs to properly rebuild the
# NIS databases. Don't change these unless you have a good reason.
***************
*** 114,120 ****
# If you don't want some of these maps built, feel free to comment
# them out from this list.
! all: passwd group hosts rpc services netid protocols mail \
# netgrp shadow publickey networks ethers bootparams printcap \
# amd.home auto.master auto.home auto.local passwd.adjunct \
# timezone locale netmasks
--- 114,120 ----
# If you don't want some of these maps built, feel free to comment
# them out from this list.
! all: passwd shadow group hosts rpc services netid protocols mail \
# netgrp shadow publickey networks ethers bootparams printcap \
# amd.home auto.master auto.home auto.local passwd.adjunct \
# timezone locale netmasks
--------------------------------
このままだとすべてのホストからNIS情報を引き出すことができるようになっているので
NIS情報を引き出せるホストを限定するために /var/yp/securenets を作成して
以下を書き込みます。
255.255.255.0 192.168.200.0
これで指定したネットワークに属するホストだけがNIS情報を引き出せるようになりました。
ここでサーバーデーモンの起動
/etc/rc.d/init.d/ypserv start
/etc/rc.d/init.d/yppasswdd start
そして、起動時に自動でデーモンが走るように以下を実行
chkconfig ypserv on
chkconfig yppasswdd on
/usr/lib64/yp/ypinit -m を実行
NISサーバーの情報を確認される。今回は、サーバーは1台体制(冗長化無し)なのでNISDOMAINで設定した内容が表示されていればおk
B) ファイヤーウォールの設定
portmapper が使う tcp と udp 111番ポートへの通信を受け入れるようにしておく。
C ) クライアントの準備 (サーバーマシンでも実行する)
./rssh.sh ' echo "NISDOMAIN = clnet" >> /etc/sysconfig/network '
./rssh.sh "sed -ei 's/\(USENIS=\)no/\1yes/' /etc/sysconfig/authconfig "
./rssh.sh 'echo "domain clnet server bwhead" > /etc/yp.conf'
slaveノード用のNS設定ファイルを作成して配布する。
mkdir tmp
cd tmp
cp /etc/nsswitch.conf tmp.conf
スレーブ用設定ファルの変更。以下がオリジナルのファイルとの差分
------差分----------
*** /etc/nsswitch.conf 2013-04-29 15:43:35.280253996 +0900
--- tmp.conf 2013-05-06 22:59:03.979813909 +0900
***************
*** 30,38 ****
#shadow: db files nisplus nis
#group: db files nisplus nis
! passwd: files nis
! shadow: files nis
! group: files nis
#hosts: db files nisplus nis dns
hosts: files dns nis
--- 30,38 ----
#shadow: db files nisplus nis
#group: db files nisplus nis
! passwd: nis files
! shadow: nis files
! group: nis files
#hosts: db files nisplus nis dns
hosts: files dns nis
--------------------
cd
./rscp.sh ./tmp/tmp.conf /etc/nsswitch.conf
ypbind をインストールする
./rssh.sh 'yum -y install rpcbind'
./rssh.sh '/etc/rc.d/init.d/rpcbind start'
./rssh.sh 'chkconfig rpcbind on'
./rssh.sh 'yum -y install ypbind'
./rssh.sh '/etc/rc.d/init.d/ypbind start'
./rssh.sh 'chkconfig ypbind on'
D) ユーザーの追加 (適宜)
NISサーバーにて
useradd newuser_name
passwd newuser_name
以上で通常通りユーザーを追加した後
cd /var/yp
make
でNIS DBに追加したユーザーの情報を追加する。
これでもログイン出来ない場合は、まずクライアントマシンで
ypcat passwd して追加したユーザーの情報が反映されれているかチェック。
追加されているにもかかわらずログイン出来ない場合は、
/etc/ypserv.conf中の
files: 30
を
files: 0
に変更してキャッシュを無効にする。
[5] NFS の構築
すべてのノードでホームディレクトリを共有できるようにする。
A) サーバーの構築
yum -y install nfs-utils
共有するディレクトリに関する設定を行う /etc/exports に以下を追加
/home 192.168.200.0/24(rw,sync,no_root_squash,no_all_squash)
/home … 共有するディレクトリの指定
192.168.200.00/24 … 共有を許すネットワーク
sync … 遅延書き込みをしない
no_root_squash … root の特権を行こうにする
no_all_squash … そのままの権限でアクセスさせる
/etc/idampd.conf にドメインの設定をする。デフォルトでは、「Domain = 」を含む行がコメントアウトされているので有効にしてドメインを記述する。
Domain = clnet
起動していないデーモンを起動しておく
/etc/rc.d/init.d/rpcbind start
/etc/rc.d/init.d/nfslock start
/etc/rc.d/init.d/nfs start
起動時にデーモンが自動で起動するようにしておく
chkconfig rpcbind on
chkconfig nfslock on
chkconfig nfs on
B) クライアントの準備
サーバーマシンからシェルスクリプトを用いて実行する
./rssh.sh 'yum -y install nfs-utils'
先ほど編集したNFSサーバーの /etc/idamp
./rssh.sh '/etc/rc.d/init.d/rpcbind start'
./rssh.sh '/etc/rc,d/init.d/nfslock start'
./rssh.sh '/etc/rc.d/init.d/netfs start'
./rssh..sh 'chkconfig rpcbind on'
./rssh.sh 'chkconfig nfslock on'
../rssh.sh 'chkconfig netfs on'
ここからは、各ノードに直接ログインして操作する
まずは、サーバーのパーティションをマウントできるかをテスト
mount -t nfs bwhead:/home /home
df -h
でマウントされたかどうかを確認する。
次に起動時に自動でマウントされるように/etc/fstab を変更
以下の行を追記
bwhead:/home /home nfs bg,intr 0 0
bg… NFSでのマウントが失敗した時にバックグランドで試行を繰り返す。
intr … 停止しているプロセスをkillするために、割り込みを可能にする。
0 … dump頻度
0 … fchkパスのフィールド
さらにインストール時に切った/home のパーティションをマウントしないようにコメントアウトしておく。
これ以上ができたNFSクライアントマシンを再起動して無事にマウントされるかを確認しておく。
[6] OpenMPI のインストール(headノード含めすべてのノードで)
その前にgcc とg++ ,makeのインストール
yum -y install gcc
yum -y install gcc-c++
yum -y install make
今回は、OpenMPI Ver.1.6.4 を用いる。
wget http://www.open-mpi.org/software/ompi/v1.6/downloads/openmpi-1.6.4.tar.gz
cd openmpi-1.6.4
./configure --prefix=/usr/local
make all # 複数コアある場合は make -j num_proc all で並列コンパイルできるらしい
[7] サンプルプログラムの実行
実行用専用ユーザーをNISサーバーにて作る
useradd cltest
passwd cltest
NIS DBへの反映
cd /var/yp ; make
ヘッドノードにてログアウトしてcltestでログインする
以下のソースを作成
-----main.c------------
#include <stdio.h>
#include <mpi.h>
int main(int argc, char **argv){
int rank, size, namelen;
char name[256];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Get_processor_name(name, &namelen);
sleep(5);
printf("This is %d of %d on %s\n", rank, size, name);
MPI_Finalize();
return 0;
}
----------------------
mpicc main.c
でコンパイル。
実行前にライブラリサーチPATHをbashrcに追加
export LD_LIBRARY_PATH=/usr/local
source .bashrc
そして、root権限を得て/usr/local/etc/openmpi-default-hostfile (headノード)
にどのユーザーのジョブでも常に実行させたシステム共通の計算ノードを追記する。
以下例
bwhead
bwslv01
bwslv02
本来なら、ヘッドノードは、ジョブ実行のみで計算は行わないがホストPCのリソースがそんなに潤沢ではないためヘッドノードも追加した。
mpirun -np 3 a,out
これで下記の様に各ノードでの出力が表示されればクラスタ構築一応完了。
---実行結果-----
This is 0 of 3 on bwhead.clnet
This is 1 of 3 on bwslv01
This is 2 of 3 on bwslv02
----------------
[7]参考
http://kuni255.blogspot.jp/2013/04/iptables.html
目標は、
「MPIライブラリを使ったサンプルプログラムを複数ノードで実行する」
今回構築するクラスタの概要は、
*ヘッドノード、スレーブノード2ノードの計3ノード
*すべてのノードは、CentOS release 6.4 minimal
*ヘッドノードは、/home のみをNFSにて共有する(ディスクレスに挑戦したかったけどまた今度
ネットワークは、下図の様になる。

各ノードのスペックは、
node name CPU RAM HDD
bwhead amd64 (1 core)*1 2 Gbyte 50Gbyte x 2*2
bwslv01 amd64 (1 core) 1 Gbyte 50 GByte
bqslv02 amd64 (1 core) 1Gbyte 50 GByte
*1 型名になっていないのは、今回構築したノードすべてが仮想マシンだからです。
*2 /home 用に1台、/用に1台
-目次-
[0] HeadノードへのOSのインストール

一番上の項目を選択

イメージをマウントしてますが、メディアテスト

Testを選択

OK


Continueを選択

OK

Next

Engilish

キーボードレイアウトの選択英字配列キーボードを使ってます。

Basic strage device

Yesを選択

ホスト名 ここでは、間違っていたので後でbwheadに修正しました。

タイムゾーン Tokyo/Asia

root のパスワード

パーティション構成を決めます

今回は、このように切ることにしました

Formatを押下

Write changes to diskを押下

Nextを押下

インストール中です

インストール完了 再起動します

再起動後 ログイン状況
[1] Head ノードの設定
A) ネットワークインターフェースの設定
前述のネットワーク構成図に沿って設定します。
/etc/sysconfig/network-scripts/ifcfg-eth0
ONBOOT=yes
BOOTPROTO=dhcp
/etc/sysconfig/network-scripts/ifcfg-eth1
ONBOOT=yes
BOOTPROTO=static
IPPADDR=192.168.200.1
NETMASK=255.255.255.0
B) /etc/hosts の編集
以下を追加
192.168.200.1 bwhead
192.168.200.2 bwslv01
192.168.200.3 beslv02
上記の編集を反映させるためにネットワークサービスを再始動
/etc/init.d/networking restart
C) DHCPサーバーのインストール
slaveノードへのOSのインストールは、物理マシンでの構築の演習としてPXEによるネットワークブートとします。ネットワークブートでは、ブートローダーの場所等の情報を配布するのにDHCPを用います。そこでDHCPサーバーを構築します。
yum list dhcp
でパッケージを検索
yum install dhcp
そして、設定ファイルを作成
---- /etc/dhcp/dhcpd.conf ------
#
# DHCP Server Configuration file.
# see /usr/share/doc/dhcp*/dhcpd.conf.sample
# see 'man 5 dhcpd.conf'
#
DHCPDARGS=eth1;
# network boot setttings
allow booting;
allow bootp;
option option-128 code 128 = string;
option option-129 code 129 = text;
next-server 192.168.200.1;
filename "pxelinux.0";
subnet 192.168.200.0 netmask 255.255.255.0{
# default gateway
option routers 192.168.200.1;
option subnet-mask 255.255.255.0;
option domain-name-servers 192.168.100.1;
range 192.168.200.100 192.168.200.254;
default-lease-time 21600;
max-lease-time 43200;
host bwslv01{
hardware ethernet 08:00:27:9C:25:55;
option host-name "bwslv01";
fixed-address 192.168.200.2;
}
host bwslv02{
hardware ethernet 08:00:27:29:4E:37;
option host-name "bwslv02";
fixed-address 192.168.200.3;
}
}
------------------------------------
設定ファイルの構文チェック
service dhcpd configtest
service dhcpd start
chkconfig dhcpd on
dhcpの使うポートを開けておく
iptables -I INPUT -i eth1 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
再起動時に設定が無効にならないように
/etc/init.d/iptables save
ファイヤーウォールの再起動
/etc/init.d/iptables restart
D) tftpサーバーのインストール
ネットワークブートにおいてブートローダ等を配布するのに必要
yum install tftp tftp-server
/etc/xinetd.d/tfptd
chkconfig xinetd on
service xnetd start
chkconfig tftp on
E) slave ネットワークブートのための準備
syslinuxをインストールします。
yum install syslinux
PXEブートにブートローダ関係の必要なファイルをtftpの公開ディレクトリにコピーします。
cp /usr/lib/syslinux/pxelinux.0 /var/lib/tftpboot
cp /usr/lib/syslinux/menu.c32 /var/lib/tftpboot
cp /usr/lib/syslinux/memdisk /var/lib/tftpboot
cp /usr/lib/syslinux/mboot.c32 /var/lib/tftpboot
cp /usr/lib/syslinux/chain.c32 /var/lib/tftpboot
OS関係の必要なファイルをtftpサーバーの公開ディレクトリに取ってきます。
yum install wget
mkdir -p /tftpboot/images/centos/x86_64/6.4
cd /var/lib/tftpboot/images/centos/
wget http://linux.mirrors.es.net/centos/6.4/os/x86_64/images/pxeboot/initrd.img
wget http://linux.mirrors.es.net/centos/6.4/os/x86_64/images/pxeboot/vmlinuz
ブートローダメニューの設定ファイルを作成
---/var/lib/tftpboot/pxelinux.cfg/default---
default menu.c32
prompt 0
timeout 300
INTIMEOUT local
MENU TITLE PXE Menu
LABEL local
MENU LABEL Boot from local hard disk drive
LOCALBOOT 0
LABEL CentOS 6.4 x86_64
MENU LABEL CentOS 6.4 x86_64
KERNEL images/centos/6.4/x86_64/vmlinuz
APPEND load initrd=images/centos/6.4/x86_64/initrd.img devfs=nomount
--------------------------------------
tftp(udp 69番ポート)を開ける
iptables -A INPUT -m state --state NEW -i eth0 -p udp --dport 69 -j ACCEPT
再起動時に設定が無効にならないように
/etc/init.d/iptables save
ファイヤーウォールの再起動
/etc/init.d/iptables restart
フォワーディングを有効にする
-- /etc/sysctl.conf--
# Controls IP packet forwarding
net.ipv4.ip_forward = 1 # 0 から 1に変更
----------------------
[2] slavve ノードのOSインストール

仮想マシンを起動したら即座にF12キーを押下する

PXEブートするために「l」キーを押下する

予め行った設定が適切に行われていれば
tftpサーバーからブートロードがDLされてメニューが表示される
CentOSを選択して、Enterを押下

インストール中に用いる言語の選択

キーボードレイアウトの選択

OSインストーラーのメディア種別を選択。セキュリティ的には、
あまり宜しくないけどHTTPで取ってきます。

ネットワーク設定
IPv4は、DHCPにします。

NIC設定中

インストーラーイメージ取得中
これ以降は、Headノードと同じGUIなインストーラーが起動しての同じインストールとなる。
[3] ssh でのhead から slave へのパスワード無しログイン
MPIライブラリのデータの移動、設定ファイルの配布のための仕組みを構築します。
よくr系コマンドが用いられますが、自分の環境では、rootでのパスワード無しログインが
できるようにすることを断念したため、sshを用います。
A) slave ノードへssh-server のインストール
yum install openssh-server
scpを使うため
yum install openssh-client
/etc/ssh/sshd_configの以下のコメントをはずす
#PermitRootLogin yes -> PermitRootLogin yes
chkconfig ssh on
service sshd start
試しにrootで全てのslaveノードにログインしてみる
ssh root@192.168.200.n # n は、整数
ログインしたまま後の作業の準備
cd $HOME
mkdir .ssh
B) head ノードでの作業
公開鍵生成
ssh-keygen -b 1024 -t rsa
鍵のパスフレーズは空にしておく
公開鍵を全てのslaveノードに配布しておく。
scp ~/.ssh/id_rsa.pub root@192.168.200.n:.ssh/authorized_keys
クラスタは、外からの開始される接続を許可しないネットワーク内で運用するのでとりあえずSElinuxは無効化しておく。
setenforce 0
そして、起動後も無効になるように/etc/selinux/configのSELINUXTYPEを下記のようにdisabledに変更しておく。
SELINUXTYPE=diabled
C)シェルスクリプトの作成
各ノードに同様の実行するためのシェルスクリプトを用意( rshでも実現可能だが自分の環境では、rootでの実行がPermission Denied ど言われで実現できなかった
----${HOME}/utils/rssh.sh-----
#!/bin/bash
BEGIN_ADDR=2
END_ADDR=3
ADDR_PREFIX="192.168.200."
for i in `seq $BEGIN_ADDR $END_ADDR`
do
DST_ADDR="$ADDR_PREFIX$i"
echo "Processing for $DST_ADDR"
ssh $DST_ADDR<<EOF
$*
EOF
done
---------------------------
chmod 744 ${HOME}/utils/rssh.sh
各ノードにファイルコピーするためのコマンド
---${HOME}/utils/rsscp.sh---
#!/bin/bash
SRC_FILE=$1
DST_PATH=$2
BEGIN_ADDR=2
END_ADDR=3
ADDR_PREFIX="192.168.200."
for i in `seq $BEGIN_ADDR $END_ADDR`
do
DST_ADDR="$ADDR_PREFIX$i"
echo "Copying $SRC_FILE -> $DST_ADDR:$DST_PATH"
scp $SRC_FILE $DST_ADDR:$DST_PATH
done
--------------------------
D) /etc/hosts の配布
/etc/hosts を作成して
${HOME}/utils/rsscp.sh /etc/hosts /etc/hosts
[4] NIS を用いたアカウント一元管理
A) サーバーの構築
アカウントを一括管理するためにNISサーバーを構築する
まずは、サーバーのインストール
yum install ypserv
ドメインの設定 このドメインは、DNSとは関係がない
ypdomainname clnet
/etc/sysconfig/network に 先ほど設定したNISドメインを追加
NISDOMAIN = clnet
/var/yp/Makefile の編集(下記がオリジナルのファイルとの差分)
-----差分-----------------------
*** Makefile.org 2013-04-27 17:41:09.642037547 +0900
--- Makefile 2013-04-27 17:42:41.594036564 +0900
***************
*** 39,49 ****
# Should we merge the passwd file with the shadow file ?
# MERGE_PASSWD=true|false
! MERGE_PASSWD=true
# Should we merge the group file with the gshadow file ?
# MERGE_GROUP=true|false
! MERGE_GROUP=true
# These are commands which this Makefile needs to properly rebuild the
# NIS databases. Don't change these unless you have a good reason.
--- 39,49 ----
# Should we merge the passwd file with the shadow file ?
# MERGE_PASSWD=true|false
! MERGE_PASSWD=false
# Should we merge the group file with the gshadow file ?
# MERGE_GROUP=true|false
! MERGE_GROUP=false
# These are commands which this Makefile needs to properly rebuild the
# NIS databases. Don't change these unless you have a good reason.
***************
*** 114,120 ****
# If you don't want some of these maps built, feel free to comment
# them out from this list.
! all: passwd group hosts rpc services netid protocols mail \
# netgrp shadow publickey networks ethers bootparams printcap \
# amd.home auto.master auto.home auto.local passwd.adjunct \
# timezone locale netmasks
--- 114,120 ----
# If you don't want some of these maps built, feel free to comment
# them out from this list.
! all: passwd shadow group hosts rpc services netid protocols mail \
# netgrp shadow publickey networks ethers bootparams printcap \
# amd.home auto.master auto.home auto.local passwd.adjunct \
# timezone locale netmasks
--------------------------------
このままだとすべてのホストからNIS情報を引き出すことができるようになっているので
NIS情報を引き出せるホストを限定するために /var/yp/securenets を作成して
以下を書き込みます。
255.255.255.0 192.168.200.0
これで指定したネットワークに属するホストだけがNIS情報を引き出せるようになりました。
ここでサーバーデーモンの起動
/etc/rc.d/init.d/ypserv start
/etc/rc.d/init.d/yppasswdd start
そして、起動時に自動でデーモンが走るように以下を実行
chkconfig ypserv on
chkconfig yppasswdd on
/usr/lib64/yp/ypinit -m を実行
NISサーバーの情報を確認される。今回は、サーバーは1台体制(冗長化無し)なのでNISDOMAINで設定した内容が表示されていればおk
B) ファイヤーウォールの設定
portmapper が使う tcp と udp 111番ポートへの通信を受け入れるようにしておく。
C ) クライアントの準備 (サーバーマシンでも実行する)
./rssh.sh ' echo "NISDOMAIN = clnet" >> /etc/sysconfig/network '
./rssh.sh "sed -ei 's/\(USENIS=\)no/\1yes/' /etc/sysconfig/authconfig "
./rssh.sh 'echo "domain clnet server bwhead" > /etc/yp.conf'
slaveノード用のNS設定ファイルを作成して配布する。
mkdir tmp
cd tmp
cp /etc/nsswitch.conf tmp.conf
スレーブ用設定ファルの変更。以下がオリジナルのファイルとの差分
------差分----------
*** /etc/nsswitch.conf 2013-04-29 15:43:35.280253996 +0900
--- tmp.conf 2013-05-06 22:59:03.979813909 +0900
***************
*** 30,38 ****
#shadow: db files nisplus nis
#group: db files nisplus nis
! passwd: files nis
! shadow: files nis
! group: files nis
#hosts: db files nisplus nis dns
hosts: files dns nis
--- 30,38 ----
#shadow: db files nisplus nis
#group: db files nisplus nis
! passwd: nis files
! shadow: nis files
! group: nis files
#hosts: db files nisplus nis dns
hosts: files dns nis
--------------------
cd
./rscp.sh ./tmp/tmp.conf /etc/nsswitch.conf
ypbind をインストールする
./rssh.sh 'yum -y install rpcbind'
./rssh.sh '/etc/rc.d/init.d/rpcbind start'
./rssh.sh 'chkconfig rpcbind on'
./rssh.sh 'yum -y install ypbind'
./rssh.sh '/etc/rc.d/init.d/ypbind start'
./rssh.sh 'chkconfig ypbind on'
D) ユーザーの追加 (適宜)
NISサーバーにて
useradd newuser_name
passwd newuser_name
以上で通常通りユーザーを追加した後
cd /var/yp
make
でNIS DBに追加したユーザーの情報を追加する。
これでもログイン出来ない場合は、まずクライアントマシンで
ypcat passwd して追加したユーザーの情報が反映されれているかチェック。
追加されているにもかかわらずログイン出来ない場合は、
/etc/ypserv.conf中の
files: 30
を
files: 0
に変更してキャッシュを無効にする。
[5] NFS の構築
すべてのノードでホームディレクトリを共有できるようにする。
A) サーバーの構築
yum -y install nfs-utils
共有するディレクトリに関する設定を行う /etc/exports に以下を追加
/home 192.168.200.0/24(rw,sync,no_root_squash,no_all_squash)
/home … 共有するディレクトリの指定
192.168.200.00/24 … 共有を許すネットワーク
sync … 遅延書き込みをしない
no_root_squash … root の特権を行こうにする
no_all_squash … そのままの権限でアクセスさせる
/etc/idampd.conf にドメインの設定をする。デフォルトでは、「Domain = 」を含む行がコメントアウトされているので有効にしてドメインを記述する。
Domain = clnet
起動していないデーモンを起動しておく
/etc/rc.d/init.d/rpcbind start
/etc/rc.d/init.d/nfslock start
/etc/rc.d/init.d/nfs start
起動時にデーモンが自動で起動するようにしておく
chkconfig rpcbind on
chkconfig nfslock on
chkconfig nfs on
B) クライアントの準備
サーバーマシンからシェルスクリプトを用いて実行する
./rssh.sh 'yum -y install nfs-utils'
先ほど編集したNFSサーバーの /etc/idamp
./rssh.sh '/etc/rc.d/init.d/rpcbind start'
./rssh.sh '/etc/rc,d/init.d/nfslock start'
./rssh.sh '/etc/rc.d/init.d/netfs start'
./rssh..sh 'chkconfig rpcbind on'
./rssh.sh 'chkconfig nfslock on'
../rssh.sh 'chkconfig netfs on'
ここからは、各ノードに直接ログインして操作する
まずは、サーバーのパーティションをマウントできるかをテスト
mount -t nfs bwhead:/home /home
df -h
でマウントされたかどうかを確認する。
次に起動時に自動でマウントされるように/etc/fstab を変更
以下の行を追記
bwhead:/home /home nfs bg,intr 0 0
bg… NFSでのマウントが失敗した時にバックグランドで試行を繰り返す。
intr … 停止しているプロセスをkillするために、割り込みを可能にする。
0 … dump頻度
0 … fchkパスのフィールド
さらにインストール時に切った/home のパーティションをマウントしないようにコメントアウトしておく。
これ以上ができたNFSクライアントマシンを再起動して無事にマウントされるかを確認しておく。
[6] OpenMPI のインストール(headノード含めすべてのノードで)
その前にgcc とg++ ,makeのインストール
yum -y install gcc
yum -y install gcc-c++
yum -y install make
今回は、OpenMPI Ver.1.6.4 を用いる。
wget http://www.open-mpi.org/software/ompi/v1.6/downloads/openmpi-1.6.4.tar.gz
cd openmpi-1.6.4
./configure --prefix=/usr/local
make all # 複数コアある場合は make -j num_proc all で並列コンパイルできるらしい
[7] サンプルプログラムの実行
実行用専用ユーザーをNISサーバーにて作る
useradd cltest
passwd cltest
NIS DBへの反映
cd /var/yp ; make
ヘッドノードにてログアウトしてcltestでログインする
以下のソースを作成
-----main.c------------
#include <stdio.h>
#include <mpi.h>
int main(int argc, char **argv){
int rank, size, namelen;
char name[256];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Get_processor_name(name, &namelen);
sleep(5);
printf("This is %d of %d on %s\n", rank, size, name);
MPI_Finalize();
return 0;
}
----------------------
mpicc main.c
でコンパイル。
実行前にライブラリサーチPATHをbashrcに追加
export LD_LIBRARY_PATH=/usr/local
source .bashrc
そして、root権限を得て/usr/local/etc/openmpi-default-hostfile (headノード)
にどのユーザーのジョブでも常に実行させたシステム共通の計算ノードを追記する。
以下例
bwhead
bwslv01
bwslv02
本来なら、ヘッドノードは、ジョブ実行のみで計算は行わないがホストPCのリソースがそんなに潤沢ではないためヘッドノードも追加した。
mpirun -np 3 a,out
これで下記の様に各ノードでの出力が表示されればクラスタ構築一応完了。
---実行結果-----
This is 0 of 3 on bwhead.clnet
This is 1 of 3 on bwslv01
This is 2 of 3 on bwslv02
----------------
[7]参考
http://kuni255.blogspot.jp/2013/04/iptables.html
登録:
コメント (Atom)